
在不断发展的大型语言模型领域,DeepSeek V3 vs LLaMA 4 已成为开发人员、研究人员和人工智能爱好者最热门的对决之一。无论您是要优化快速推理、细致入微的文本理解,还是要创造性地讲故事,DeepSeek V3 与 LLaMA 4 的基准测试结果都备受关注。但这不仅仅是原始数据的问题–性能、速度和使用案例的匹配度在选择正确模型的过程中都起着至关重要的作用。这篇 DeepSeek V3 与 LLaMA 4 的对比文章将深入探讨了它们的优势和权衡,以便您决定哪种功能更适合您的工作流程(从快速原型开发到生产就绪的人工智能应用)。
什么是DeepSeek V3?
DeepSeek V3.1是DeepSeek团队推出的最新人工智能模型。它旨在突破推理、多语言理解和上下文感知的极限。它拥有庞大的 560B 参数变换器架构和 100 万个令牌上下文窗口,能够精准、深入地处理高度复杂的任务。
主要功能
- 更智能的推理:与以前的版本相比,多步骤推理能力提高了 43%。非常适合解决数学、代码和科学领域的复杂问题。
- 海量上下文处理:通过 100 万个标记上下文窗口,它可以理解整本书、代码库或法律文件,而不会遗漏上下文。
- 精通多语种:支持 100 多种语言,接近母语流利程度,包括亚洲语言和低资源语言的重大升级。
- 减少幻觉:改进后的训练可将幻觉减少 38%,使反应更加准确可靠。
- 多模式功能:可理解文本、代码和图像,满足开发人员、研究人员和创作者的实际需求。
- 为速度而优化:推理速度更快,同时不影响质量。
什么是Llama 4?
Llama 4 是 Meta 最新推出的开放式大型语言模型,采用名为 Mixture-of-Experts (MoE) 的强大新架构设计。它有两个变体:
- Llama 4 Maverick:这是一个高性能模型,使用 128 个专家,在约 4000 亿个有效参数中拥有 170 亿个参数。
- Llama 4 Scout:更轻便、更高效的版本,拥有相同的 170 亿个活动参数,取自总计约 1,090 亿个活动参数的较小数据池,只有 16 个专家。
这两个模型都使用早期融合技术实现原生多模态,这意味着它们可以同时处理文本和图像输入。它们在覆盖 200 种语言的 40 万亿个词库中进行了训练,并对 12 种主要语言进行了微调,包括阿拉伯语、印地语、西班牙语和德语。
主要功能
- 多模态设计:可同时理解文本和图像。
- 海量训练数据:基于 40T 标记进行训练,支持 200 多种语言。
- 语言专业化:针对 12 种主要全球语言进行了微调。
- 高效的 MoE 架构:每个任务只使用一个专家子集,提高了速度和效率。
- 可在低端硬件上部署:Scout 支持即时 int4/int8 量化,适用于单 GPU 设置。Maverick 为优化硬件提供了 FP8/BF16 权重。
- 变压器支持:与最新的 Hugging Face 变压器库(v4.51.0)完全集成。
- 支持 TGI:通过文本生成推理实现高吞吐量生成。
- Xet 存储后端:通过高达 40% 的重复数据删除功能加快下载和微调速度。
如何使用DeepSeek V3和LLaMA 4
既然您已经了解了DeepSeek V3和LLaMA 4的功能,现在让我们来看看如何毫不费力地开始使用它们,无论是用于研究、开发还是只是测试它们的功能。
如何使用最新的DeepSeek V3?
- 网站:在 deepseek.com 免费测试更新后的V3。
- 移动应用程序:可在iOS和安卓系统上使用,已更新以反映3月24日发布的版本。
- 应用程序接口(API):在 api-docs.deepseek.com 上使用 model=’deepseek-chat’ 。定价仍为 0.14 美元/百万输入代币(推广期至 2025 年 2 月 8 日,但不排除延期的可能)。
- HuggingFace: 从这里下载“DeepSeek V3 0324”权重和技术报告。
有关分步说明,请参阅本文章 。
如何使用Llama 4模型?
- Llama.meta.com:这是 Meta 官方的 Llama 模型中心。
- Hugging Face:Hugging Face 承载着可立即使用的 Llama 4 版本。您可以直接在浏览器中使用推理端点测试模型,或通过 Transformers 库部署模型。
- Meta 应用:Llama 4 模型还为 WhatsApp、Instagram、Messenger 和 Facebook 中的 Meta AI 助手提供支持。
- 网页:您可以使用网页界面直接访问最新的 Llama 4 模型。
DeepSeek 与 LLaMA 4:任务对比
DeepSeek V3 和 LLaMA 4 Scout 都是强大的多模态模型,但它们在实际任务中的表现如何?
为了找出答案,我在五个不同的挑战性任务中对这两个模型进行了测试:
- 光与能量悖论:评估解释物理概念时的科学推理和清晰度。
- 数句子中的复数词:测试编码能力、效率和结构。
- 总结一个故事:评估总结能力和自然语言理解能力。
- 金融问题(单利与复利):考察数学推理和教学清晰度。
- 向高中生解释过度拟合:测量为初学者简化复杂的 ML 概念的能力。
每个任务都突出了一个独特的优势或局限性,帮助我们了解哪个模型在哪个领域表现出色。
任务 1:光与能量悖论
输入提示词:Light has no mass, so it also has no energy, according to Einstein. But how can sunlight warm the Earth without energy?
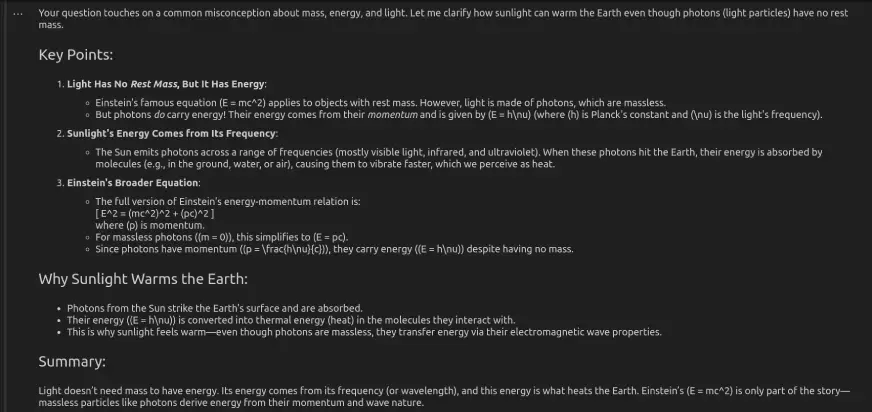
Deepseek v3输出:
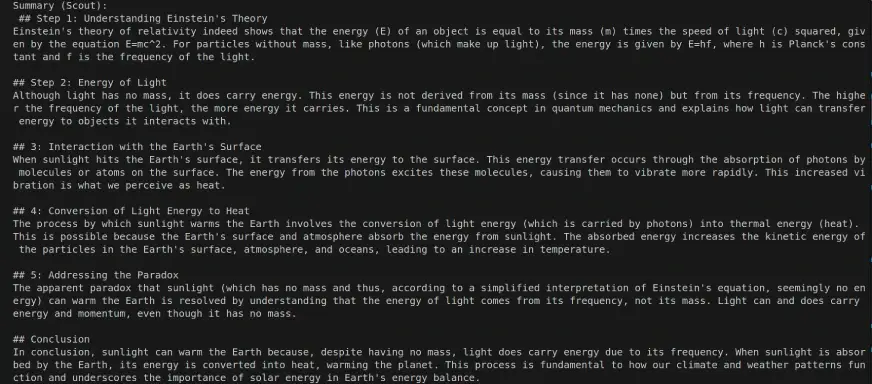
LLaMA 4 Scout输入:
对比
| 对比项 | LLaMA 4 Scout | DeepSeekV3 |
| 物理学解析 | 提到 E = mc² 和 E = hf;光子没有静止质量,但携带能量。 | 包括 E = mc²、E = hf 和 E² = (mc²)² + (pc)²;解释光子动量(p = hν/c)。 |
| 光子加热 | 地球吸收光子,导致气候变暖。 | 吸收增加了分子振动–详细解释了热传递。 |
| 澄清误解 | 通过指出光子没有质量却具有能量来解决这个问题。 | 阐明能量来自动量,而非静止质量-更好的科学框架。 |
| 语调与风格 | 教育性强,简单明了,循序渐进。 | 技术性更强,但仍然通俗易懂,包括方程式和摘要。 |
评价 :
- LLaMA非常适合希望获得清晰概念性讲解的学习者。
- DeepSeek则更适合希望获得更多科学细节、更技术性、以物理学为导向的解释的读者。
结果:LLaMA 4 Scout – 1 | DeepSeek V3 – 0
任务 2:计算句子中的复韵词
输入提示词:Write a Python function that takes a sentence as input and returns the number of palindromic words in it. A palindromic word is a word that reads the same forwards and backwards, like “madam” or “level”. Ignore case and punctuation.
Deepseek v3输出:
这是 DeepSeek V3 提供的代码:
import re def count_palindromic_words(sentence): # Remove all punctuation and split into words words = re.findall(r'\b\w+\b', sentence.lower()) count = 0 for word in words: if word == word[::-1]: count += 1 return count # Example usage: sentence = "Madam Anna and her civic racecar saw a level deed at noon in a kayak." print(count_palindromic_words(sentence))Copy Code
输出:
10
LLaMA 4 Scout输出:
这是 LLaMA 4 Scout 提供的代码:
import re
import string
def count_palindromic_words(sentence: str) -> int:
"""
Count the number of palindromic words in a sentence.
Args:
sentence (str): The input sentence.
Returns:
int: The number of palindromic words.
"""
# Convert to lower case and remove punctuation
sentence = sentence.lower()
sentence = re.sub('['+string.punctuation+']', '', sentence)
# Split into words
words = sentence.split()
# Initialize count
count = 0
# Check each word
for word in words:
# Compare word with its reverse
if word == word[::-1]:
count += 1
return count
# Example usage
def main():
sentence = "Madam Anna and her civic racecar saw a level deed at noon in a kayak."
print(f"Number of palindromic words: {count_palindromic_words(sentence)}")
if __name__ == "__main__":
main()Copy Code
输出:
Number of palindromic words: 10
对比
| 对比项 | LLaMA 4 Scout | DeepSeekV3 |
| 文字处理 | 使用 .split()、string.punctuation 和 re.sub 进行清理 | 使用 re.findall(r’\b\w+\b’, …)进行高效的单词提取 |
| 代码风格 | 使用 main() 和 docstrings 构建;更冗长 | 紧凑、简约、注重功能 |
| 导入与效率 | 同时使用 re 和 string;由于需要额外的步骤,所以时间稍长 | 仅使用 re;通过结合清理和拆分提高效率 |
| 最佳用例 | 非常适合学习和文档齐全的代码库 | 最适合快速、高效的实用脚本 |
结论:两种实现方式都是正确有效的,选择取决于你是优先考虑可读性还是简洁性。
结果:LLaMA 4 Scout – 1 | DeepSeek V3 – 1
任务 3:概括一个故事
故事:https://www.newyorker.com/humor/daily-shouts/a-short-story-written-with-thought-to-text-technology
Deepseek v3输出:

LLaMA 4 Scout输出:

对比
| 对比项 | DeepSeek 输出 | LLaMA 输出 |
| 语调与焦点 | 抽象、情绪化;侧重于孤独和自我怀疑等主题 | 叙事性和描述性;更清晰地描绘人物的处境 |
| 细节层次 | 概括性(律师事务所、失败的职业生涯) | 具体(星巴克、丽贝卡和史蒂夫-鲍曼等名字) |
| 风格 | 分析和总结式 | 故事驱动,富有表现力 |
| 最佳使用案例 | 快速情感概述 | 丰富的人物快照,更多的背景 |
结论:LLaMA 提供了更丰富的故事回顾。DeepSeek 效率高,以主题为导向。
结果:LLaMA 4 Scout – 2 | DeepSeek V3 – 1
任务 4:金融问题(单利与复利)
输入提示词:Sum of ₹10,000 is invested for 3 years. The interest rate is 8% per annum. If the interest is calculated annually (simple interest), what is the total amount after 3 years? Now, if the interest is calculated annually and added to the principal at the end of each year (compound interest), what is the total amount after 3 years? Which method yields a higher return?
Deepseek v3反馈结果:

LLaMA 4 Scout反馈结果:
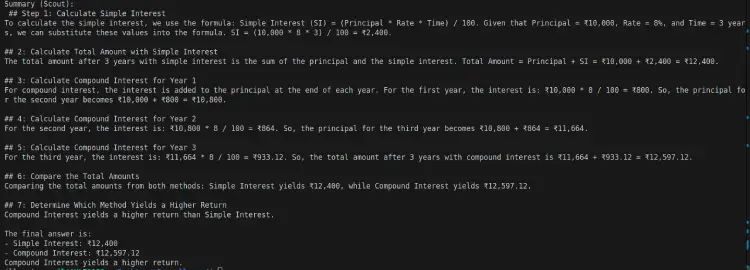
对比
| 对比项 | DeepSeek V3 | LLaMA 4 |
|---|---|---|
| 风格 | 简明扼要,公式驱动 | 分步叙述 |
| CI 计算 | 使用直接公式 A = P(1 + r)^n | 使用年增长率 |
| 适用于 | 快速数学参考 | 概念学习和清晰度 |
| 输出长度 | 更简短 | 较长,解释性 |
结论
- 如果想快速获得基于公式的答案,请选择 DeepSeek V3。
- 如果您想逐步清晰地了解过程,请选择 LLaMA 4。
结果:LLaMA 4 Scout – 2 | DeepSeek V3 – 2
任务 5:向一名高中生解释过度拟合问题
输入提示词:Explain the concept of overfitting in machine learning to a high school student using an example.
Deepseek v3反馈结果:

LLaMA 4 Scout反馈结果:
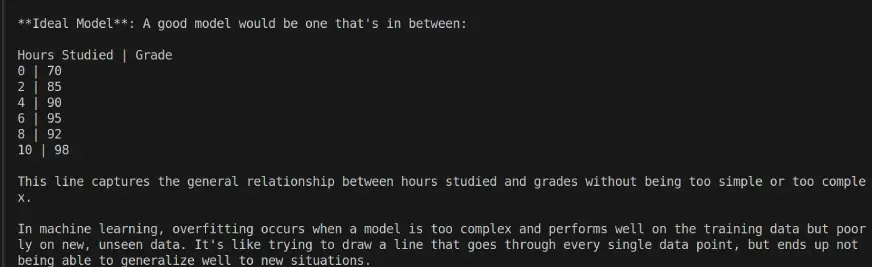
对比
| 对比项 | LLaMA 4 | DeepSeek |
| 风格 | 数字/图表类比 | 真实世界的故事类比 |
| 无障碍 | 中等(假定有一定的逻辑理解能力) | 高(与日常学习习惯相关) |
| 概念的深度 | 专业术语详尽 | 概念深刻,语言简化 |
| 适用于 | 对视觉/数学有兴趣的学习者 | 普通读者和初学者 |
结论
- 对于高中生来说,DeepSeek 基于类比的解释让过拟合的概念更容易消化和记忆。
- 对于有机器学习背景的人来说,LLaMA 的结构化解释可能更有见地。
结果: LLaMA 4 Scout – 2 | DeepSeek V3 – 3
总体比较
| 对比项 | DeepSeek V3 | LLaMA 4 Scout |
| 风格 | 简洁、公式化 | 循序渐进,娓娓道来 |
| 最佳 | 快速、技术性结果 | 学习、概念清晰 |
| 深度 | 科学准确性高 | 吸引更多受众 |
| 理想用户 | 研究人员、开发人员 | 学生、教育工作者 |
选择 DeepSeek V3,了解速度、技术任务和更深入的科学见解。选择 LLaMA 4 Scout,以获得清晰的教育、逐步的解释和更广泛的语言支持。
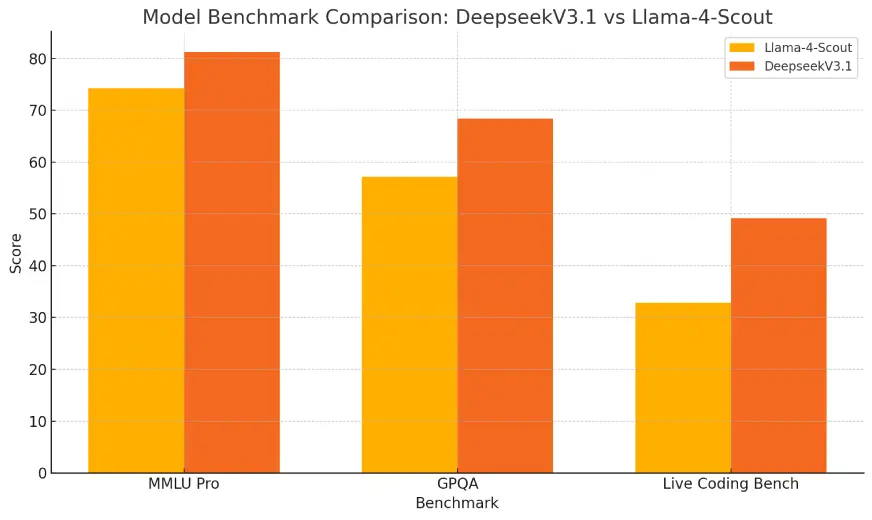
基准测试比较:DeepSeek V3.1与Llama-4-Scout-17B-16E的比较
在所有三个基准测试类别中,DeepSeek V3.1始终优于Llama-4-Scout-17B-16E,显示出更强的推理能力、数学问题解决能力和更好的代码生成性能。
小结
DeepSeek V3.1和LLaMA 4 Scout都展示了非凡的能力,但它们在不同的应用场景中大放异彩。如果你是开发人员、研究人员或追求速度、精度和更深入的科学推理的高级用户,DeepSeek V3 是你的理想选择。它拥有巨大的上下文窗口,降低了幻觉率,并采用公式优先的方法,非常适合技术深挖、长文档理解和科学、技术、工程和数学领域的问题解决。
另一方面,如果您是学生、教育工作者或普通用户,希望获得清晰、有条理的解释和易懂的见解,LLaMA 4 Scout 是您的不二之选。它循序渐进的风格、教育性的语气和高效的架构使其特别适合学习、编码教程和多语言应用。












暂无评论内容