

想象一下,您只有一张人物照片,却希望看到他们在视频中栩栩如生,自然地移动和表达情感。ByteDance 的最新人工智能模型 DreamActor-M1 可以将静态图像转化为动态逼真的动画,从而实现这一愿望。本文将探讨 DreamActor-M1 的工作原理、技术设计以及这种强大技术所带来的重要伦理问题。
DreamActor-M1如何工作?

Link: Source
把 DreamActor-M1 想象成数字动画师。它利用智能技术了解照片中的细节,比如你的脸部和身体。然后,它会观看别人的移动视频(这被称为“驱动视频”),并学习如何让照片中的人以同样的方式移动。这意味着它可以让照片中的人走路、挥手,甚至跳舞,同时保持其独特的神态和表情。
DreamActor-M1 重点解决了旧动画模型难以解决的三大问题:
- 整体控制能力:动画应捕捉人物的每个部分,从面部表情到全身动作。
- 多尺度适应性:无论照片是面部特写还是全身特写,都应能很好地表现。
- 长期一致性:视频不应在帧与帧之间“闪烁”。随着时间的推移,动作应该看起来流畅可信。
DreamActor-M1的主要功能
DreamActor-M1 采用了 3 种先进技术:
混合引导系统
DreamActor-M1 将多种信号结合在一起,实现了精确、富有表现力的动画效果:
- 微妙的面部表现捕捉微表情和面部动作。
- 三维头部球体模拟头部的三维方向和运动。
- 三维人体骨骼提供全身姿势指导。
这些都是从驾驶视频中提取的,用作控制动画输出的条件输入,从而实现逼真的效果。
多尺度适应性
为确保在不同图像尺寸和身体比例下的通用性:
- 该模型使用不同的输入集进行训练,包括以面部为中心的视频数据和全身视频数据。
- 渐进式训练策略能适应粗略和精细尺度的运动,保持外观的一致性。
长期时间一致性
保持外观的长期一致性是视频生成的主要挑战之一。DreamActor-M1 通过以下方式解决了这一问题
- 利用运动感知参考帧和互补视觉特征。
- 不仅预测单个帧,而且预测具有全局时间感知的序列,以防止闪烁或抖动。
让我们来看几个例子
这些视频展示了人工智能生成的对话头模型,能够制作高度逼真的面部动画、精确的唇部同步和自然的情感映射。利用先进的生成技术和运动数据,它是虚拟影响者、数字化身、交互式聊天机器人、游戏和电影应用的理想选择,可提供流畅、令人信服的类人表情。
示例 1
示例 2
点击此处查看更多示例。
DreamActor-M1结构
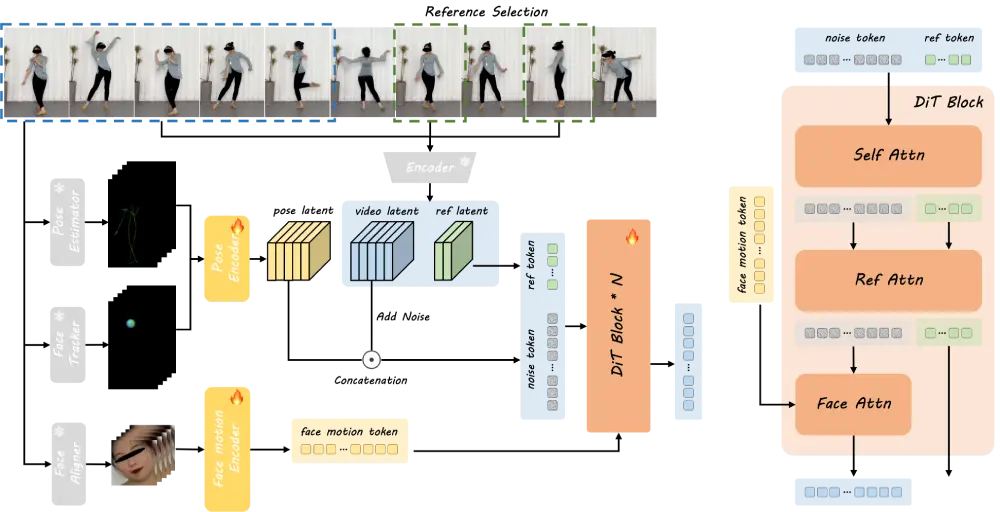
Link: Source
DreamActor-M1 主要由五个部分组成,它们共同将一张照片转换成动态逼真的视频。这些部件根据其功能可分为三组:
1. 理解运动的部分
- 面部运动分支:该部分会查看要复制的视频(称为驱动视频),并找出面部表情,如微笑、眨眼或说话等。它将这些表情转化为模型可以用来制作面部动画的小块信息。
- 姿势分支:该分支可跟踪身体和头部在 3D 中的移动方式,如转头、挥臂或行走。它将这些动作分解成点和角度,这样人工智能就知道如何在新视频中移动人的身体。
2. 理解外观的部分
- 参考网:这部分研究输入的照片,并将其制作成动画。它会找出人物的长相:衣服、发型和面部细节。它会妥善保存这些信息,使人物在视频的每一帧中都保持一致。
3. 制作视频的部件
- 视频生成器(扩散变换器):这是构建视频的主要引擎。它将面部动作、身体姿势和照片外观整合在一起,创建出流畅、逼真的视频帧。它使用一个特殊的系统,一步一步地进行微小的修改,直到最终图像看起来真实为止。
- 低分辨率 UNet(训练时使用):系统仅在模型学习阶段使用该辅助工具。它可以帮助人工智能进行练习,一开始先处理小尺寸、低质量的图像。一旦模型完成训练,就不再需要这部分。
为何令人兴奋?
这项技术对于制作电影或有趣的视频来说就像魔法一样神奇。想象一下,电影制片人用它来创造场景,而不需要演员来完成每个动作。研究人员对 DreamActor-M1 进行了多项基准测试,发现它几乎在所有方面都优于现有方法:
- 图像质量:它能生成更清晰、更细腻的图像,在 FID、SSIM 和 PSNR(衡量逼真度和准确度的指标)方面得分更高。
- 唇部同步:与以前的模型相比,它的动画嘴部能更好地匹配语音。
- 稳定性:它能在各帧中保持外观一致,不会出现闪烁或奇怪的动作。
DreamActor-M1与其他视频生成器的比较
与 DreamActor-M1 一样,Meta 的 MoCha 也是近来大受欢迎的图像视频生成器。这两种模式都是通过视频或运动特征等驱动信号,将单个输入图像转换成动画。它们的共同目标都是以自然可信的方式为静态肖像制作动画,因此具有直接的可比性。以下是两个模型的并排比较:
| 特征 | DreamActor-M1 | MoCha |
| 主要目标 | 通过单张图像制作全身和面部动画 | 高精度面部再现 |
| 输入类型 | 单张图像 + 驾驶视频 | 单一图像 + 动作提示或驾驶视频 |
| 面部动画质量 | 通过流畅的唇部同步和情感映射实现高度真实感 | 高度精细的面部动作,尤其是眼睛和嘴部周围 |
| 全身支持 | 是 – 包括头部、手臂和身体姿势 | 否– 主要集中在面部区域 |
| 姿势鲁棒性 | 能很好地处理较大的姿势变化和遮挡 | 对大动作或侧视图敏感 |
| 运动控制方法 | 双运动分支(面部表情 + 3D 身体姿势) | 带有运动感知编码的 3D 面部呈现 |
| 渲染风格 | 基于扩散的全局一致性渲染 | 专注于面部区域的高精细渲染 |
| 最佳应用案例 | 会说话的数字头像、电影、角色动画 | 面部交换、重现、情感克隆 |
虽然 DreamActor-M1 和 MoCha 擅长的领域略有不同,但它们都代表了个性化视频生成领域的巨大进步。SadTalker 和 EMO 等模型也属于这一领域,但它们主要侧重于面部表情,有时会牺牲动作的流畅性。HoloTalk 是另一种新兴模式,具有很高的唇部同步精度,但不能像 DreamActor-M1 那样提供全身控制。相比之下,DreamActor-M1 集面部逼真度、肢体动作和姿势适应性于一身,是目前最全面的解决方案之一。
使用DreamActor-M1时的道德考量
DreamActor-M1 虽然令人兴奋,但它也引发了严重的伦理问题,因为它只用一张照片就能制作出逼真的视频。以下是一些关键问题:
- 同意和身份滥用:DreamActor-M1 可用于在人们不知情或未经其许可的情况下制作视频。有人可能会在自己从未录制过的视频中把朋友、公众人物或名人制作成动画。
- 深度伪造风险:DreamActor-M1 的输出效果逼真,因此很难区分人工智能生成的视频和真实视频。这项技术可能会产生有害的深度伪造(假视频),从而误导或欺骗人们。
- 需要透明度:对人工智能生成视频的任何使用都应向观众明确披露。这包括添加水印、免责声明或数字元数据,以确定内容是合成的。如果没有这种透明度,观众可能会误以为视频是真实的,从而失去信任。
- 在媒体中负责任地使用:电影制作、游戏和动画等创意产业应负责任地使用该技术。内容创作者、工作室和平台必须采用最佳实践和保障措施,防止技术被滥用。
小结
DreamActor-M1 是人工智能动画领域的一次巨大飞跃,为已经蓬勃发展的 GenAI 领域带来了又一次突破。它将复杂的运动建模和扩散变换器与丰富的视觉理解融为一体,将静态照片转化为富有表现力的动态视频。虽然它具有创造性的潜力,但在使用时应提高认识并承担责任。随着研究的不断发展,DreamActor-M1 已成为人工智能如何在下一代媒体制作中实现逼真性和创造性的有力范例。












暂无评论内容