

Meta 的 Llama 4 是开源人工智能领域的一次重大飞跃,它提供了多模态支持、专家混合架构和海量上下文窗口。但真正让它与众不同的是它的可访问性。无论您是在构建应用程序、运行实验还是扩展人工智能系统,都有多种方法可以通过 API 访问 Llama 4。在本教程中,我将向您展示如何在一些最好的 API 平台(如 OpenRouter、Hugging Face、GroqCloud 等)上访问和使用 Llama 4 Scout 和 Maverick 模型。
Llama 4的主要特点和功能
- 原生多模态与早期融合:从一开始就使用早期融合技术处理文本和图像。每个提示最多支持 5 张图片–非常适合图片说明、视觉问答等。
- 专家混合(MoE)架构:将每项输入路由到一小部分专家网络,从而提高效率。
- Scout:17B 活动/总计 109B,16 位专家
- Maverick:17B 激活/总计 400B,128 位专家
- Behemoth:288B 活动/ ~2T 总计(训练中)
- 扩展上下文窗口:轻松处理长输入。
- Scout:最多 1 千万代币
- Maverick:多达 100 万个词库
- 多语言支持:本机支持 12 种语言,并在 200 多种语言的数据基础上进行了训练。在图像-文本任务中,英语性能最佳。
- 专家图像基础:将文本链接到特定图像区域,实现精确的视觉推理和基于图像的高质量答案。
Llama 4在LMSYS Chatbot Arena中排名第二
在图像推理(MMMU:73.4%)、代码生成(LiveCodeBench:43.4%)和多语言理解(多语言 MMLU:84.6%)等关键任务中,Meta 的 Llama 4 Maverick 均优于GPT-4o 和 Gemini 2.0 Flash。
它还能在单个 H100 上高效运行,成本更低,部署更快。这些结果凸显了 Llama 4 在强大功能、多功能性和经济性之间的平衡,使其成为生产型人工智能工作负载的有力选择。
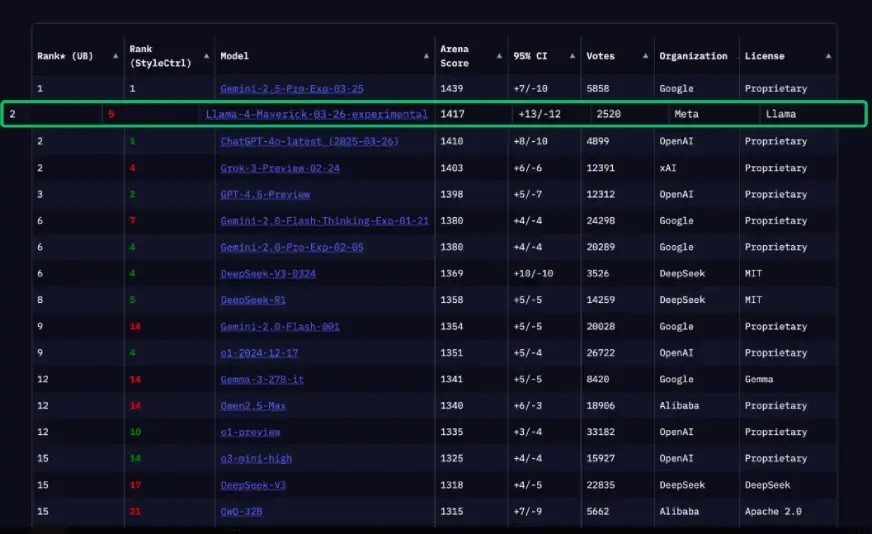
Source: Llmarena
如何使用Meta的Llama 4模型?
Meta 针对不同用户的需求和技术专长,通过各种平台和方法提供了访问 Llama 4 的途径。
通过Meta人工智能平台访问Llama 4模型
试用 Llama 4 的最简单方法是通过 Meta 的人工智能平台 meta.ai。您可以立即开始与助手聊天,无需注册。它在 Llama 4 上运行,你可以通过询问“你是哪个模型?Llama 3 还是 Llama 4?”助手会回答:“我是在 Llama 4 上构建的”。不过,这个平台也有其局限性:没有 API 访问权限,自定义选项也很少。
从Llama.com下载模型权重
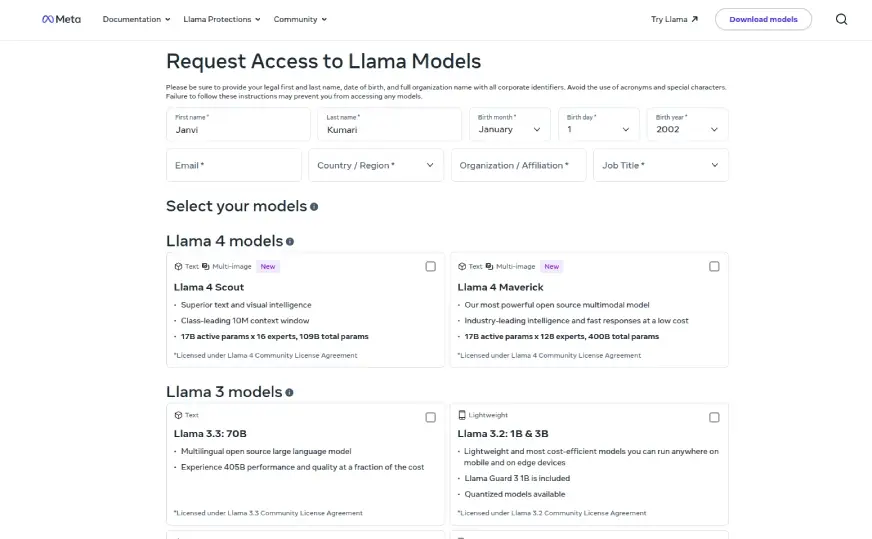
您可以从 llama.com 下载模型权重。您需要先填写一份申请表。获得批准后,您就可以获得 Llama 4 Scout 和 Maverick。Llama 4 Behemoth 可能会稍后推出。这种方法可以完全控制。你可以在本地运行,也可以在云端运行。但它最适合开发人员。没有聊天界面。
通过API提供商访问Llama 4模型
有几个平台提供了访问 Llama 4 的 API,为开发人员提供了将模型集成到自己的应用程序中的工具。
OpenRouter
OpenRouter.ai 提供对 Llama 4 模型 Maverick 和 Scout 的免费 API 访问。注册后,您可以探索可用的模型、生成 API 密钥并开始请求。OpenRouter 还包含一个内置聊天界面,可让您在将响应集成到应用程序之前轻松进行测试。
Hugging Face
要通过“Hugging Face”访问“Llama 4”,请按照以下步骤操作:
1. 创建一个Hugging Face账号
如果还没有注册,请访问 https://huggingface.co 并注册一个免费帐户。
2. 找到 Llama 4 模型库
登录后,搜索官方 Meta Llama 组织或特定的 Llama 4 模型,如 meta-llama/Llama-4-Scout-17B-16E-Instruct。你也可以在 Llama 网站或 Hugging Face 的博客上找到官方资源库的链接。
3. 请求访问模型
浏览模型页面,点击“请求访问”按钮。您需要在表格中填写以下详细信息,如法定全名、出生日期、组织全名(无缩写或特殊字符)、国家、所属单位(如学生、研究员、公司)和职务。
您还需要仔细阅读并接受《Llama 4 Community License Agreement》。填写完所有字段后,点击“Submit”请求访问。请确保信息准确无误,因为提交后可能无法编辑。
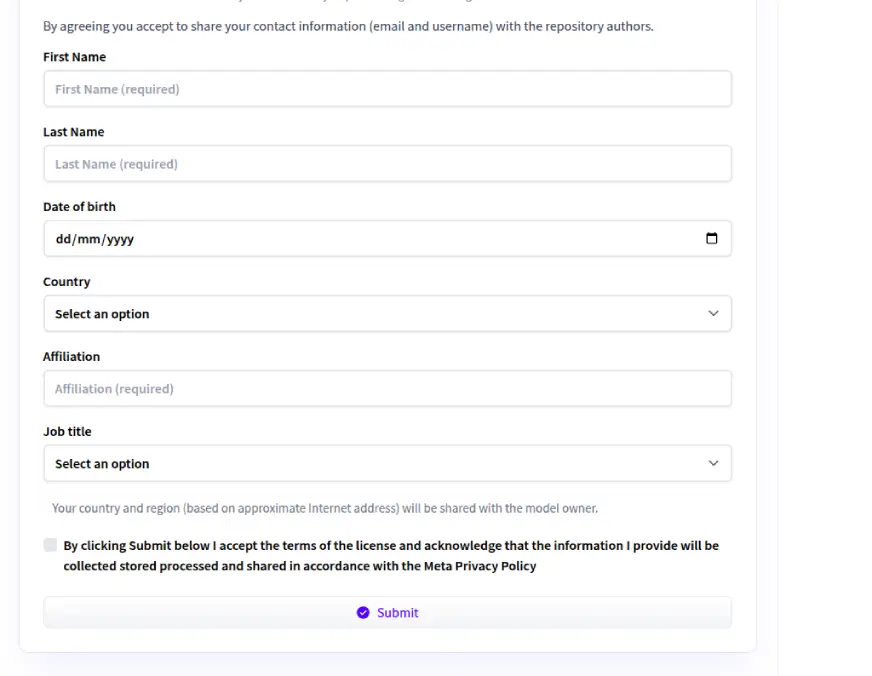
4. 等待批准
提交申请后,Meta 将对您的申请进行审核。如果自动批准访问,您将立即获得访问权。否则,审核过程可能需要几小时到几天。访问批准后,您将收到电子邮件通知。
5. 以编程方式访问模型
要在代码中使用模型,首先要安装所需的库:
pip install transformers Then, authenticate using your Hugging Face token: from huggingface_hub import login login(token="YOUR_HUGGING_FACE_ACCESS_TOKEN") (You can generate a "read" token from your Hugging Face account settings under Access Tokens.)
现在,加载并使用下图所示的模型:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct" # Replace with your chosen model tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Inference input_text = "What is the capital of India?" input_ids = tokenizer.encode(input_text, return_tensors="pt") output = model.generate(input_ids, max_length=50, num_return_sequences=1) print(tokenizer.decode(output[0], skip_special_tokens=True))
替代访问选项:
- Hugging Face 推理 API:某些 Llama 4 模型可能提供 API 访问,但可用性和成本取决于 Meta 的政策。
- 下载模型权重:一旦访问权限获得批准,您就可以从模型库下载权重供本地使用。
完成这些步骤并满足批准标准后,您就可以在 Hugging Face 平台上成功访问和使用 Llama 4 模型。
Cloudflare Workers AI
Cloudflare 通过其 Workers AI 平台将 Llama 4 Scout 作为无服务器 API 提供。您只需进行最少的设置,就能通过 API 调用调用模型。内置的 AI 游戏场地可用于测试,无需账户即可开始基本访问,非常适合轻量级或实验性使用。
Snowflake Cortex AI
对于 Snowflake 用户,可以在 Cortex AI 环境中访问 Scout 和 Maverick。这些模型可通过 SQL 或 REST API 使用,实现与现有数据管道和分析工作流的无缝集成。这对已经利用 Snowflake 平台的团队尤其有用。
Amazon SageMaker JumpStart 和 Bedrock
Llama 4 已集成到亚马逊 SageMaker JumpStart 中,并计划在 Bedrock 中提供。通过 SageMaker 控制台,您可以轻松部署和管理模型。如果您已经在 AWS 上进行构建,并希望将 LLM 嵌入到云原生解决方案中,这种方法尤其有用。
GroqCloud
GroqCloud 提供 Scout 和 Maverick 的早期访问权限。您可以通过 GroqChat 或 API 调用使用它们。注册后可免费使用,付费层级可提供更高的限制,因此既适合探索,也适合扩展到生产中。
经过简单的注册程序后,Together AI 即可提供 Scout 和 Maverick 的 API 访问权限。开发人员在注册后可获得免费点数,并可立即开始使用已发放密钥的 API。它对开发人员友好,并提供高性能推理。
Replicate
Replicate 承载着 Llama 4 Maverick Instruct,可使用其 API 运行。定价基于令牌使用量,因此你只需为你所使用的令牌付费。对于希望进行实验或构建轻量级应用的开发人员来说,这是一个不错的选择,而且无需前期基础设施成本。
Fireworks AI
Fireworks AI 还通过无服务器 API 提供 Llama 4 Maverick Instruct。开发人员可以根据 Fireworks 的文档进行设置,并迅速开始生成响应。对于那些希望在不管理服务器的情况下大规模运行 LLM 的人来说,这是一个简洁的解决方案。
访问Llama 4模型的平台和方法
PlatformModels AvailableAccess MethodKey Features/NotesMeta AIScout, MaverickWeb Interface即时访问,无需注册,有限的自定义,无API访问。Llama.comScout, MaverickDownload需要批准,全模型权重访问,适用于本地/云部署。 OpenRouterScout,MaverickAPI,Web 界面免费 API 访问,无等待名单,可能适用费率限制。Hugging FaceScout,MaverickAPI,DownloadGated access form,Inference API,下载权重,适用于开发人员。Cloudflare Workers AIScoutAPI,Web 界面(Playground)无服务器,处理基础设施、API 请求。 Amazon SageMaker JumpStartScout, MaverickConsoleAvailable now.Amazon BedrockScout, MaverickComing SoonFully managed, serverless option.GroqCloudScout, MaverickAPI, Web Interface (GroqChat, Console)注册后免费访问,付费层级用于扩展。 Together AIScout、MaverickAPIR需要账户和API密钥,新用户可免费使用。ReplicateMaverick InstructAPIP按令牌收费。Fireworks AIMaverick Instruct (Basic)API, On-demand Deployment详细访问说明请参考官方文档。
| 平台 | 支持模型 | 访问方式 | 关键特征/备注 |
|---|---|---|---|
| Meta AI | Scout, Maverick | 网页 | 即时访问、无需注册、有限定制、无 API 访问权限。 |
| Llama.com | Scout, Maverick | 下载 | 需要批准,完全模式权重访问,适合本地/云部署。 |
| OpenRouter | Scout, Maverick | API,网页 | 免费 API 访问,无等待名单,可能有费率限制。 |
| Hugging Face | Scout, Maverick | API,下载 | 有限制的访问形式,推理 API,下载权重,适用于开发人员。 |
| Cloudflare Workers AI | Scout | API,网页 (Playground) | 无服务器,处理基础设施、API 请求。 |
| Snowflake Cortex AI | Scout, Maverick | SQL Functions,REST API | Snowflake 内的集成访问,适用于企业应用。 |
| Amazon SageMaker JumpStart | Scout, Maverick | 控制台 | 现已推出。 |
| Amazon Bedrock | Scout, Maverick | 即将提供 | 完全托管、无服务器选项。 |
| GroqCloud | Scout, Maverick | API,网页 (GroqChat, Console) | 注册后可免费访问,付费层级用于扩展。 |
| Together AI | Scout, Maverick | API | 需要账户和 API 密钥,新用户可免费使用。 |
| Replicate | Maverick Instruct | API | 按令牌计价。 |
| Fireworks AI | Maverick Instruct (Basic) | API,On-demand Deployment | 详细访问说明请查阅官方文档。 |
通过API接口试用Llama 4 Scout和Maverick
在本比较中,我们将评估 Meta 的 Llama 4 Scout 和 Maverick 模型在各种任务类别(如摘要、代码生成和多模态图像理解)中的表现。所有实验均在 Google Colab 上进行。为简单起见,我们使用 userdata 访问我们的 API 密钥,其中包含对密钥的简短引用。
下面是我们如何使用 Groq 通过 Python 对每个模型进行测试的快速一瞥:
前提条件
在深入学习代码之前,请确保您已设置好以下内容:
- GroqCloud 账户
- 将您的 Groq API 密钥设置为环境变量 (GROQ_API_KEY)
- 已安装 Groq Python SDK:
pip install groq
设置:初始化Groq客户端
现在,在笔记本中初始化 Groq 客户端:
import os
from groq import Groq
# Set your API key
os.environ["GROQ_API_KEY"] = userdata.get('Groq_Api')
# Initialize the client
client = Groq(api_key=os.environ.get("GROQ_API_KEY"))
任务 1:总结长篇文档
我们向两个模型提供了一段关于人工智能进化的长文,并要求它们做出简明扼要的总结。
Llama 4 Scout
long_document_text = """"""
prompt_summary = f"Please provide a concise summary of the following document:\n\n{long_document_text}"
# Scout
summary_scout = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[{"role": "user", "content": prompt_summary}],
max_tokens=500
).choices[0].message.content
print("Summary (Scout):\n", summary_scout)
输出:

Llama 4 Maverick
# Maverick
summary_maverick = client.chat.completions.create(
model="meta-llama/llama-4-maverick-17b-128e-instruct",
messages=[{"role": "user", "content": prompt_summary}],
max_tokens=500
).choices[0].message.content
print("\nSummary (Maverick):\n", summary_maverick)
输出:

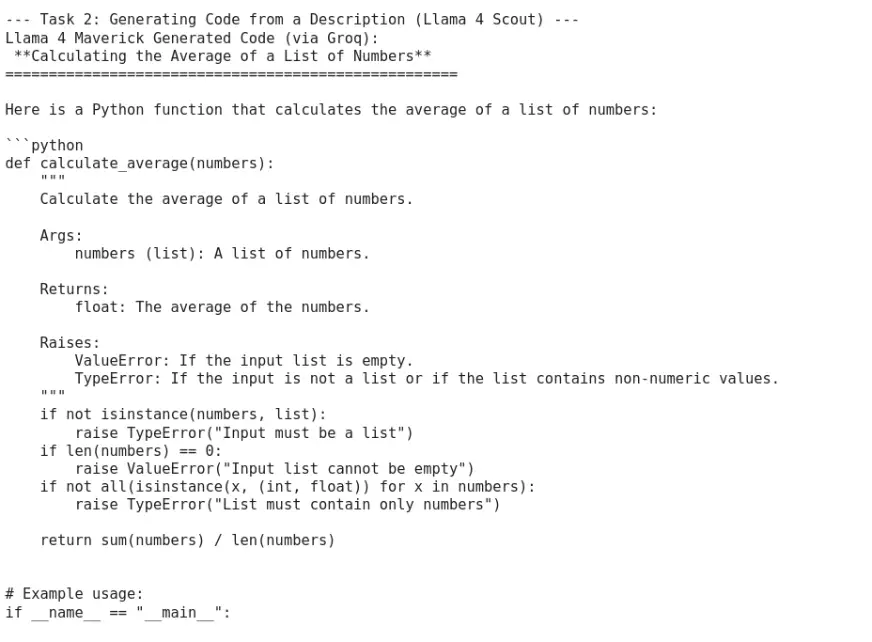
任务 2:根据描述生成代码
我们要求两个模型根据简单的功能提示编写一个 Python 函数。
Llama 4 Scout
code_description = "Write a Python function that takes a list of numbers as input and returns the average of those numbers."
prompt_code = f"Please write the Python code for the following description:\n\n{code_description}"
# Scout
code_scout = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[{"role": "user", "content": prompt_code}],
max_tokens=200
).choices[0].message.content
print("Generated Code (Scout):\n", code_scout)
输出:
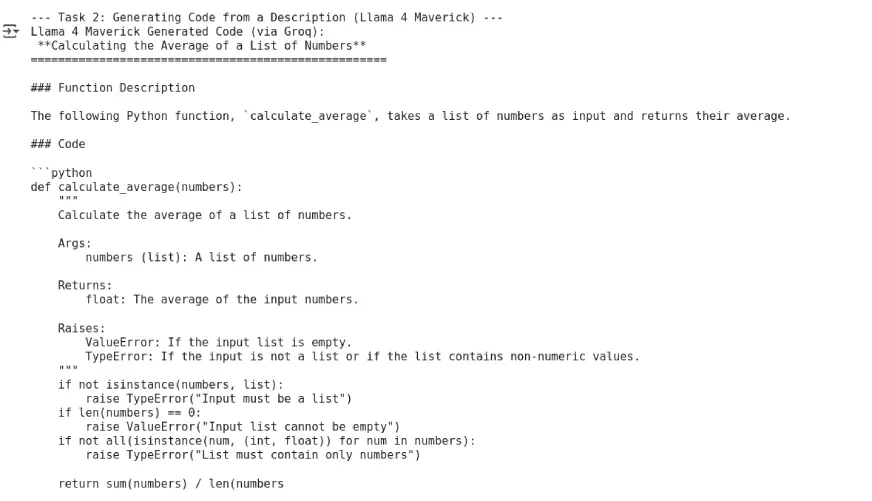
Llama 4 Maverick
# Maverick
code_maverick = client.chat.completions.create(
model="meta-llama/llama-4-maverick-17b-128e-instruct",
messages=[{"role": "user", "content": prompt_code}],
max_tokens=200
).choices[0].message.content
print("\nGenerated Code (Maverick):\n", code_maverick)
输出:
任务 3:图像理解(多模态)
我们向两个模型提供了相同的图片 URL,并要求其详细描述图片内容。
Llama 4 Scout
image_url = "https://cdn.analyticsvidhya.com/wp-content/uploads/2025/04/Screenshot-2025-04-06-at-3.09.43%E2%80%AFAM.webp"
prompt_image = "Describe the contents of this image in detail. Make sure it’s not incomplete."
# Scout
description_scout = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt_image},
{"type": "image_url", "image_url": {"url": image_url}}
]
}
],
max_tokens=150
).choices[0].message.content
print("Image Description (Scout):\n", description_scout)
输出:

Llama 4 Maverick
# Maverick
description_maverick = client.chat.completions.create(
model="meta-llama/llama-4-maverick-17b-128e-instruct",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt_image},
{"type": "image_url", "image_url": {"url": image_url}}
]
}
],
max_tokens=150
).choices[0].message.content
print("\nImage Description (Maverick):\n", description_maverick)
输出:

任务分析
| 任务 | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| 1. 长文档摘要 | 优胜者:Scout 凭借其出色的 10M 标记上下文窗口,Scout 可轻松处理大文本,确保长摘要的上下文完整性。 |
亚军 尽管语言能力很强,但 Maverick 的 1M 标记上下文窗口限制了其保留长距离依赖关系的能力。 |
| 2. 代码生成 | 亚军 Scout 能生成功能性代码,但其输出偶尔会遗漏细微的逻辑或技术工作流程中的最佳实践。 |
优胜者:Maverick Maverick专门从事开发任务,始终按照用户意图提供精确、高效的代码。 |
| 3. 图像描述(多模态) | 功能强大 虽然 Scout 可以处理图像输入并做出正确响应,但在需要精细的视觉和文本连接的场景中,其输出可能会让人感觉很一般。 |
优胜者:Maverick 作为一个原生的多模态模型,Maverick 在图像理解方面表现出色,能够生成生动、详细和上下文丰富的描述。 |
Llama 4 Scout 和 Llama 4 Maverick 都具有令人印象深刻的功能,但它们在不同的领域大放异彩。Scout 擅长处理长篇内容,这得益于其扩展的上下文窗口,使其成为总结和快速互动的理想选择。
另一方面,Maverick 在技术任务和多模态推理方面表现突出,在代码生成和图像解读方面精度更高。在两者之间做出选择,最终取决于您的具体使用情况–使用 Scout,您可以获得广度和速度;而使用 Maverick,您可以获得深度和精度。
小结
Llama 4 是人工智能进步的重要一步。它是一个具有强大功能的顶级多模态模型。它能原生处理文本和图像。它的专家混合设置非常高效。它还支持长上下文窗口。这使其功能强大而灵活。Llama 4 是开源的,可广泛访问。这有助于创新和广泛采用。Behemoth 等更大的版本正在开发中。这表明 Llama 生态系统在不断发展壮大。
常见问题
Q1. 什么是 Llama 4?
A. Llama 4 是 Meta 最新一代的大型语言模型 (LLM),代表了多模态人工智能领域的重大进步,具有原生文本和图像理解能力,采用专家混合架构以提高效率,并扩展了上下文窗口功能。
Q2. Llama 4 的主要特点是什么?
A. 主要特点包括:原生多模态与文本和图像处理的早期融合、可实现高效性能的专家混合(MoE)架构、扩展的上下文窗口(Llama 4 Scout 可提供多达 1,000 万个词库)、强大的多语言支持以及专家图像基础。
Q3. Llama 4 系列有哪些不同型号?
A. 主要模型有 Llama 4 Scout(170 亿个活动参数,总计 1,090 亿个)、Llama 4 Maverick(170 亿个活动参数,总计 4000 亿个)和较大的教师模型 Llama 4 Behemoth(2880 亿个活动参数,总计约 2 万亿个,目前正在训练中)。
Q4. 如何访问 Llama 4?
A. 您可以通过 Meta AI 平台(meta.ai)访问 Llama 4,也可以从 llama.com(经批准后)下载模型权重,还可以通过 OpenRouter、Hugging Face、Cloudflare Workers AI、Snowflake Cortex AI、Amazon SageMaker JumpStart(即将推出 Bedrock)、GroqCloud、Together AI、Replicate 和 Fireworks AI 等 API 提供商访问。
Q5. Llama 4 是如何训练的?
A. Llama 4 是在海量、多样化的数据集(多达 40 万亿个代币)上进行训练的,训练中使用了超参数优化 MetaP、多模态早期融合等先进技术,以及包括 SFT、RL 和 DPO 在内的复杂的后训练管道。












暂无评论内容