

文本生成模型是研究和应用的绝佳工具。文本生成模型的优势之一在于其能力,而这些能力来自于其架构、训练和大型数据集。这些特征决定了模型的工作方式。
TeapotAI 的开源模型就是一个很好的例子,它在 TeapotLLM 方面的工作非常突出。这是一个基于 800M 参数构建的小型语言模型。它还在合成数据上进行了微调,可以在低资源环境(包括智能手机和 CPU)中提高效率。它是执行各种任务的绝佳工具。该模型只能在给定上下文中执行问答、RAG 和信息提取。
学习目标
- 了解 TeapotLLM 的功能和独特之处。
- 探索 TeapotLLM 的模型架构和训练过程。
- 了解 TeapotLLM 中的检索增强生成(RAG) 和抗幻觉功能。
- 探索 TeapotLLM 在人工智能驱动任务中的实际应用。
- 获得运行 TeapotLLM 进行问答、RAG 和结构化数据提取的实践经验。
什么是TeapotLLM?
TeapotLLM 是最先进的 800M 高精度参数模型。这一小型语言模型旨在生成无幻觉信息。它附带有一个全面的 Python 软件包 TeapotAI,可帮助使用该模型。
该模型基于转换器架构,可执行各种自然语言处理任务。开发人员使用 Deepseek-V3 生成的 LLM 任务合成数据集,在 flan-t5 基础上对其进行了微调。
TeapotAI LLM 的特点
该模型有以下几个特点
检索增强生成
可以对该模型进行微调,以便使用自定义嵌入模型执行检索增强生成。然后,该模型可以学习从文档中提取信息来回答问题。
抗幻觉
Teapot AI 经过训练可在提供的上下文中生成文本。这有助于它避免在没有足够数据的情况下回答问题。
Pydantic提取功能
这一功能意味着 TeapotAI 有一个软件包,可为模型提供基于 pydantic 的数据提取功能。这使您可以高效、准确地从文本中获取数据。
Teapot LLM的模型架构
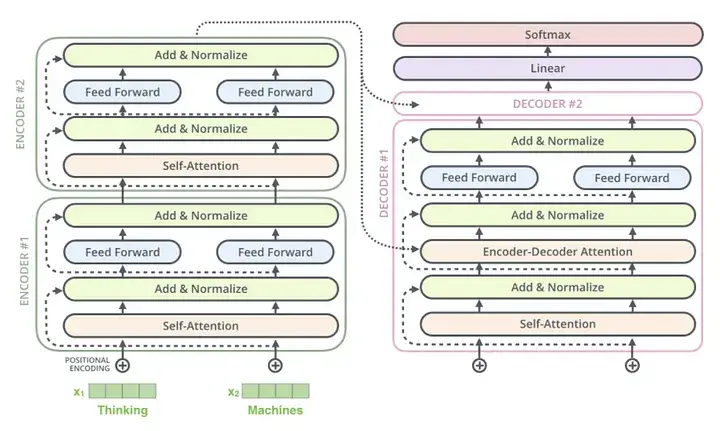
该模型是通过微调 Flan-T5 基础数据和合成数据建立的。其原理基于变压器模型;Teapot AI 也是基于编码器-解码器架构建立的。
Teapot LLM 是由 Flan-T5-Large 微调而成的专用语言模型,Flan-T5-Large 是 T5(文本到文本转换器)的一个著名指令微调变体。基础模型 Flan-T5-Large 是一种基于转换器的架构,它将每个问题都视为文本到文本问题,从而在各种自然语言处理任务中表现出色。Teapot LLM 在此基础上,利用 DeepSeek-V3 生成的大型语言模型(LLM)任务合成数据集进行了进一步完善,DeepSeek-V3 是一种先进的生成模型,以生成高质量的合成文本而著称。
Source- Click Here
该模型的结构采用了许多转换器模型常用的编码器-解码器结构来生成文本。这两个组件各司其职。编码器处理输入序列,而解码器对输出序列进行同样的处理。
在处理过程中,编码器将输入文本转换为潜在表示。解码器则将这些表征转换为特定任务的反应。
该模型的性能来自于对上下文的高度理解。这一点很容易从它的架构中得到证明,它采用了一些标准的转换器原理,如转换器注意机制、多头自注意层、前馈网络和层归一化。
如何运行Teapot LLM
该模型可用于各种应用,如回答问题、与 RAG 聊天和提取信息。我们将探讨运行该模型以执行这些任务的步骤。
准备环境
! pip install teapotai
首先,安装执行该任务所需的 Python 软件包。该命令将安装 TeapotAI,并提供执行抗幻觉任务所需的功能。
导入基本库
这一步需要从 TeapotAI 库中导入 TeapotAI 类。导入该类有助于模型执行抗幻觉问答、检索增强生成(RAG)和 JSON 提取等任务。
from teapotai import TeapotAI
背景
提供上下文是运行该模型的另一个重要步骤。这有助于模型获取执行指定任务所需的信息。
context = """The Eiffel Tower is a wrought iron lattice tower in Paris, France. It was designed by Gustave Eiffel and completed in 1889.It stands at a height of 330 meters and is one of the most recognizable structures in the world."""
这种上下文通常以多行字符串的形式出现,如上图所示,信息用三层引号封装。
模型初始化和查询
teapot_ai = TeapotAI() answer = teapot_ai.query( query="What is the height of the Eiffel Tower?", context=context )
代码初始化了 Teapotai,并使用它根据前面提到的上下文请求信息。为了得到答案,我们要打印(结果),如下所示;
print (answer)
下面是根据上下文给出的答案。

在回答包含许多文档的问题时,将此模型用作聊天工具。让我们看看如何利用这一功能运行 Teapot。
from teapotai import TeapotAI
与第一个任务一样,该代码也会导入必要的库。
上下文
这里可以提供 RAG 应用程序回答问题所依据的上下文;可以是长篇文章或文档。下面是一个示例;
documents = [ "The Eiffel Tower is located in Paris, France. It was built in 1889 and stands 330 meters tall.", "The Great Wall of China is a historic fortification that stretches over 13,000 miles.", "The Amazon Rainforest is the largest tropical rainforest in the world, covering over 5.5 million square kilometers.", "The Grand Canyon is a natural landmark located in Arizona, USA, carved by the Colorado River.", "Mount Everest is the tallest mountain on Earth, located in the Himalayas along the border between Nepal and China.", "The Colosseum in Rome, Italy, is an ancient amphitheater known for its gladiator battles.", "The Sahara Desert is the largest hot desert in the world, located in North Africa.", "The Nile River is the longest river in the world, flowing through northeastern Africa.", "The Empire State Building is an iconic skyscraper in New York City that was completed in 1931 and stands at 1454 feet tall."]
这段代码定义了一个名为“documents”的列表,其中每个元素都是一个包含事实信息的字符串。
用文档初始化Teapot以实现RAG
该初始化确保 TeapotAI 可以使用这些文档进行检索增强生成(RAG),根据给定信息回答问题,而不是根据常识生成回复。
teapot_ai = TeapotAI(documents=documents)
使用RAG获取答案
answer = teapot_ai.chat([
{
"role":"system",
"content": "You are an agent designed to answer facts about famous landmarks."
},
{
"role":"user",
"content": "What landmark was constructed in the 1800s?"
}
])
这段代码使用 TeapotAI 的“chat”方法生成结构化对话和回复。输入将是 “role”:”system” 和 “role”:”user” 字段中显示的信息。因此,答案将仅基于上述名为“documents”的列表中的给定上下文。
print(answer)
下面是根据文件给出的答案。

使用Teapot提取信息
该模型可使用 JSON 结构从上下文中提取信息。提取方法使用 Pydantic 模型来确保 Teapot 以正确的格式检索数据。它可以根据字段名称推断字段,并在提供描述时加以利用。这种方法可与 RAG 和查询功能无缝集成,以增强数据提取功能。
导入必要的库
from teapotai import TeapotAI from pydantic import BaseModel, Field
这些库有助于验证数据结构,如 pydantic 模型。BaseModel 和 Field 对于执行正确的数据格式至关重要。它们共同确保从文本中提取准确和结构化的信息。
上下文
在这里,我们提供了要从中提取信息的描述:一间公寓的详细信息。
apartment_description = """This spacious 2-bedroom apartment is available for rent in downtown New York. The monthly rent is $2500.It includes 1 bathrooms and a fully equipped kitchen with modern appliances. There is also a swimming pool at the backyard and beside the building.Pets are welcome!Please reach out to us at 555-123-4567 or john@realty.com"""
使用Pydantic模型提取数据
class ApartmentInfo(BaseModel): rent: float = Field(..., description="the monthly rent in dollars") bedrooms: int = Field(..., description="the number of bedrooms") bathrooms: int = Field(..., description="the number of bathrooms") phone_number: str
该代码使用 Pydantic 定义了“ApartmentInfo”模型,以确保结构化数据提取。各个字段阐明了每项描述,因此模型可以验证和组织提取的信息。
初始化Teapot
这将初始化 TeapotAI 模型,并允许访问结构化数据提取功能。
teapot_ai = TeapotAI()
提取公寓详细信息
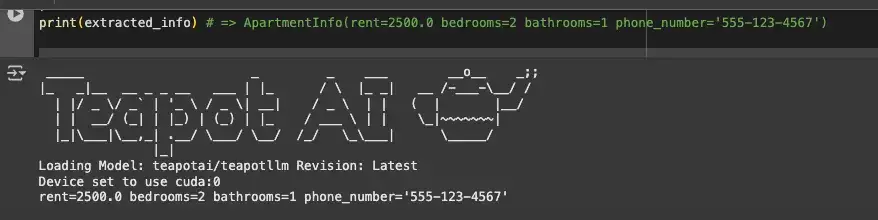
extracted_info = teapot_ai.extract( ApartmentInfo, context=apartment_description ) print(extracted_info)
在这里,我们使用 Teapot AI 模型从“ApartmentInfor”中提取结构数据,识别租金、电话号码和房间数量等关键细节。
结果如下:
TeapotLLLM的抗幻觉能力
该模型为确保准确性能而采用的一项基本技术是抗幻觉性。它允许模型仅在所提供文件或信息的背景下提供答案。
让我们用输出结果来举例说明。
from teapotai import teapotAI context = """ The Great Pyramid of Giza, built around 2560 BCE, is the oldest of the Seven Wonders of the Ancient World and the only one still standing. """
TeapotLLM的实际应用
让我们重点介绍一下该模型在现代生活中的一些常见用例。
- 人工智能驱动的聊天机器人和虚拟助手是应用该模型功能的绝佳范例。您可以根据特定上下文生成答案,从而让用户获得更准确、更正确的信息。
- 这种模式还可以通过总结冗长的文档和检索关键细节,为博客、报告和营销数据生成内容。
- 许多行业都依赖于数据驱动型系统。TeapotLLM 可以帮助从房地产文档、金融和法律系统中提取详细信息。您可以访问合同、法律文档或原始数据。
小结
这个功能强大的开源模型专为可靠的问答、检索增强生成(RAG)和结构化信息提取而设计。它的 800M 参数变换器架构使其在低资源环境中也能保持高效率,同时还能保持高精确度。
TeapotLLM 能够抵御幻觉并提供结构化输出,这使其成为人工智能驱动型应用(从聊天机器人到文档分析)中的重要工具。
- TeapotLLM 拥有8亿个参数和架构,因此重量轻,适用于CPU和智能手机等低资源环境。
- 该模型的抗幻觉能力使其更具情境感知能力,减少了答案不准确的可能性。
- 该模型使用 Pydantic 提取预定义格式的信息,因此非常适合房地产列表、金融文档和法律文本处理等应用。
资源
- Hugging Face
- Architecture
- TeapotLLM
- Github












暂无评论内容