

Agentica 和 Together AI 发布了名为 DeepCoder-14B 的开源人工智能编码模型,这是人工智能社区的一项重大进展。DeepCoder-14B 的代码生成能力与 OpenAI 的 o3-mini 和 o1 等闭源竞争对手不相上下,它将自己定位为专有模型的强大开源替代品。此外,这种新模型还确保了完全的透明度和开发人员的可访问性。在本文中,我们将探讨 DeepCoder-14B 的功能、训练和基准分数,并将其实际性能与 o3-mini 和 o1 进行比较。
什么是DeepCoder-14B?
DeepCoder-14B 是一个开源的人工智能代码生成模型,拥有 140 亿个参数。与其他专有模型不同,它具有完全的透明度,同时在功能和性能上与 OpenAI 的 o3-mini 和 o1 相当。因此,DeepCoder-14B 证明了开源人工智能编码模型无需大量计算资源就能与行业领先者竞争。
该模型采用了迭代上下文加长和超长过滤等创新训练技术,使其能够在 64K 上下文窗口中进行推理,尽管只在 32K 上下文中进行过训练。除了令人印象深刻的编码能力外,DeepCoder-14B 还在标准基准测试中展示了强大的数学推理能力。
DeepCoder-14B的主要功能
DeepCoder-14B 推进了开源人工智能编码模型的发展,其能力可与专有模型相媲美。
- 先进的训练技术:使用迭代上下文加长技术处理 64K 上下文。利用超长过滤实现 DeepCoder-14B 强化学习。
- 高质量数据集:在 24K 个经过验证的编码问题上进行训练。每个问题都有严格的质量控制和 5 个以上的测试案例。
- 完全开源:所有代码和训练数据完全透明。可在 GitHub 和 Hugging Face 上获取。
- 节省资源:支持各种量化方法,提高效率。与 TensorRT 和 vLLM 推理系统兼容。
DeepCoder-14B基准性能
下面,我们将对 DeepCoder-14B 与领先的开源和专有代码生成工具进行全面比较。这些基准评估了编码能力和跨领域问题解决能力等多个方面的性能。
| 模型 | LCB (8/1/24-2/1/25) | Codeforces Rating | Codeforces Percentile | HumanEval+ Pass@1 | AIME 2024 |
| DeepCoder-14B-Preview (ours) | 60.6 | 1936 | 95.3 | 92.6 | 73.8 |
| DeepSeek-R1-Distill-Qwen-14B | 53.0 | 1791 | 92.7 | 92.0 | 69.7 |
| o1-2024-12-17 (Low) | 59.5 | 1991 | 96.1 | 90.8 | 74.4 |
| o3-Mini-2025-1-31 (Low) | 60.9 | 1918 | 94.9 | 92.6 | 60.0 |
| o1-Preview | 42.7 | 1658 | 88.5 | 89 | 40.0 |
| Deepseek-R1 | 62.8 | 1948 | 95.4 | 92.6 | 79.8 |
| Llama-4-Behemoth | 49.4 | – | – | – | – |
| DeepCoder-1.5B-Preview | 25.1 | 963 | 28.5 | 73.0 | – |
| Deepseek-R1-Distill-Qwen-1.5B | 16.9 | 615 | 1.9 | 58.3 | 28.8 |
在多个基准测试中,DeepCoder-14B 都表现出了不俗的性能。它在 LiveCodeBench 上的得分率为 60.6%,几乎与专有替代产品相当。该模型获得了 1936 Codeforces 评级。它的 HumanEval+ 结果令人印象深刻。尽管资源有限,但这些成绩使它跻身顶级模型行列。
该模型在 AIME 数学问题上的准确率高达 73.8%,超越了编码能力。这证明了其卓越的迁移学习能力。我们的基准验证了我们的训练方法。它们证明了精心的数据整理是有效的。专业的微调技术是有效的。开源人工智能编码模型能够以适中的规模实现最先进的结果。
DeepCoder成功的背后:沙盒环境和训练方法
DeepCoder 的卓越性能源于其在培训期间采用的创新代码评估方法。
创新的代码执行基础架构
DeepCoder 傲人性能的核心在于其复杂的代码执行基础架构,它能够在强化学习过程中准确计算奖励。该系统解决了代码生成工具训练中最具挑战性的问题之一:根据多个测试用例对数千个代码样本进行可靠评估。以下是 DeepCoder 的架构和训练如何帮助解决这一问题。
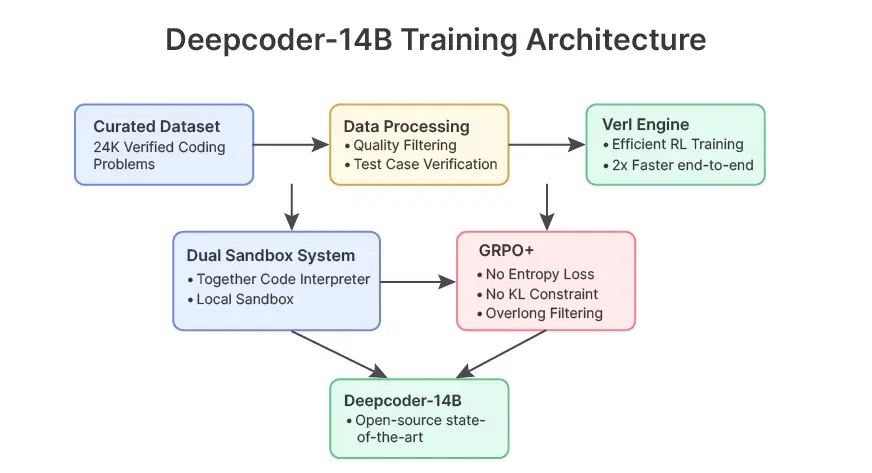
让我来详细解释一下。
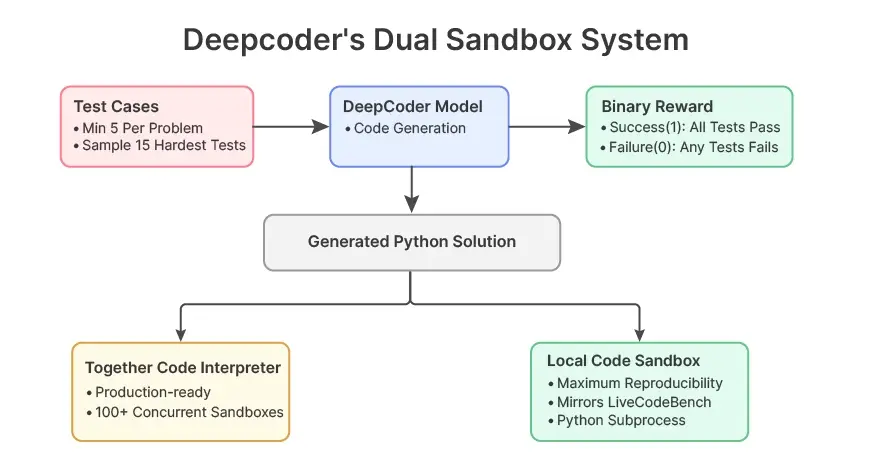
1. 双沙箱方法
DeepCoder 采用两种互补的沙箱环境,以确保代码的可靠执行:
- 共同代码解释器(Together Code Interpreter):这种生产就绪的环境能以每个问题仅 3 美分的超经济价格提供卓越的速度和安全性。团队将这一解决方案扩展到可处理 100 多个并发沙箱,每分钟可处理 1,000 多次执行。该沙箱可捕获标准输入/输出流,同时与主机系统保持严格隔离。
- 本地代码沙箱(Local Code Sandbox):为了实现最大程度的可重复性,该团队开发了一种有防护栏的 Python 子进程实现方法,与 LiveCodeBench 的评估方法完全一致。这确保了所有报告结果与行业标准基准直接对应。
2. 有原则的奖励设计
DeepCoder 不使用可能导致“奖励黑客”的部分奖励,而是采用二元结果的稀疏结果奖励模型:
- Success (1) :代码必须通过所有抽样测试用例
- Failure (0) :代码未通过任何测试或违反格式要求
对于具有大量测试套件的问题,系统会根据输入复杂度,战略性地抽取 15 个最具挑战性的测试。
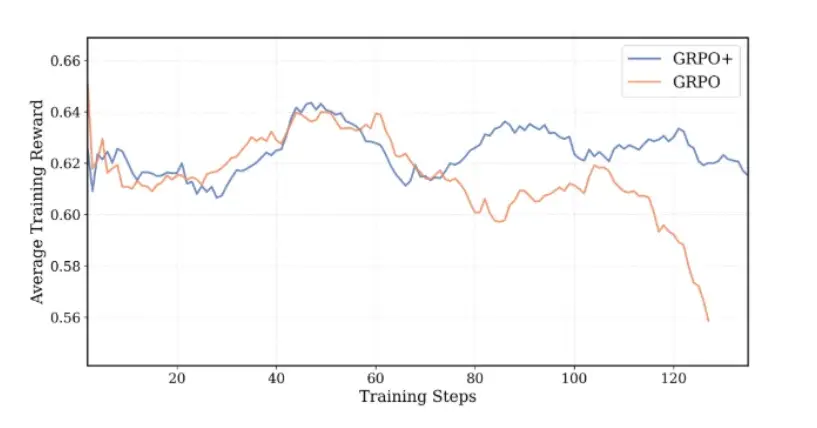
GRPO+:增强型训练算法
DeepCoder 在训练中引入了 GRPO+(广义报酬加权策略优化增强)算法。GRPO+ 是 GRPO 算法的重大演进,融合了 DAPO(扩散行为策略优化)研究的重要见解。
Source: Average training reward vs Training Steps
GRPO+ 的关键算法创新
团队进行了四项关键修改,以实现稳定的大规模训练:
- 消除熵损失:通过消除经常导致训练崩溃的熵损失项,GRPO+ 在整个训练过程中保持了一致的探索。
- 消除 KL 损失:通过消除参考策略计算,使模型不再受限于原始 SFT 模型的信任区域,从而提高了性能和训练速度。
- 超长过滤:这项技术可以防止对截断序列进行惩罚,从而保留模型的长上下文推理能力。值得注意的是,尽管 DeepCoder 只在 32K 序列上进行过训练,但它仍能泛化到 64K 上下文。
- 高剪辑:通过调整代理损失函数的上界,GRPO+ 鼓励更多的探索,同时在整个训练过程中保持稳定的熵水平。
这些算法上的改进共同创造了 DeepCoder 独特的学习模式:稳步增长的响应长度、稳定的奖励曲线和一致的标记级熵–所有这些都为其卓越的编码能力做出了贡献。
更智能的培训:同时扩展上下文和推理
训练大型模型已经是一项艰巨的任务,而训练它们在较长的上下文中进行推理则是一项更大的挑战。大多数模型要么在推理深度上打折扣,要么在上下文规模增大时碰壁。
DeepCoder 采用双管齐下的训练方法迎刃而解:
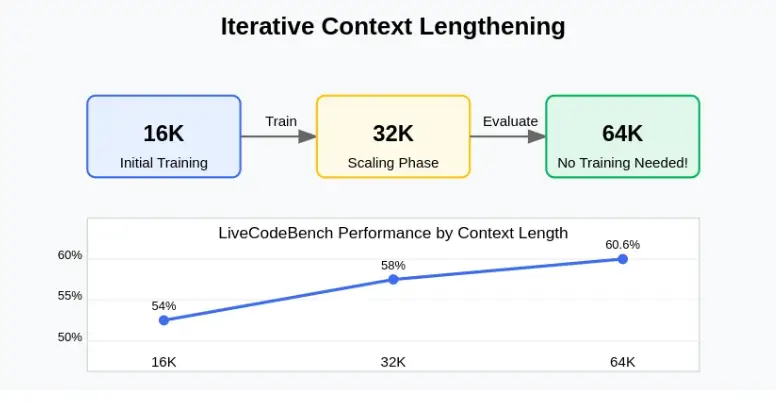
1. 迭代上下文加长
模型不是立即跳转到长上下文,而是分阶段进行训练:
- 从 16K 字节开始
- 扩展到 32K
- 在 64K 时进行评估–尽管它从未接受过这种长度的训练!
这种循序渐进的扩展方式让模型学会了如何 “在更长的文档中思考”,而不是简单地记忆标记跨度。结果不言自明:
- 16K 上下文: 在 LiveCodeBench 上的得分率为 54
- 32K 上下文: 58%
- 64K 上下文 60.6% (尽管该长度下的训练为零)
2. 超长过滤(受DAPO启发)
为避免向模型输入嘈杂、过长的样本而影响学习,DeepCoder 采用了超长过滤技术,该技术的灵感来自 DAPO。这将过滤掉超过最佳长度的训练样本,有助于保持模型学习内容的清晰度。
这些策略共同确保了模型不仅能成长,还能变得更聪明。
数据整理:从混乱到清晰、验证的编码问题
面对现实吧–互联网上的数据集编码是一团糟!无论是从 GitHub、在线评委还是论坛上抓取的数据集,通常都是不完整、有漏洞或不一致的。这对强化学习(RL)来说是个问题,因为强化学习依赖于可验证的、一致的奖励信号。
为了解决这个问题,AgenticAI 团队建立了一个定制的数据整理管道,重点包括
- 只包含通过所有测试用例的正式解决方案
- 确保每个问题至少有 5 个高质量的单元测试
- 重复训练集和测试集,以避免泄漏或评估膨胀
下面的代码显示了其数据处理管道中使用的核心验证逻辑。该功能根据质量标准对每个问题进行检查,然后才允许其进入数据集:
# Simplified data processing workflow using custom data curation pipeline def validate_problem(problem): if problem.test_cases < 5: reject() if not passes_all_tests(problem.solution): reject() if exists_in_test_split(problem): reject() return problem
这样就产生了一个包含 24,000 个编码问题的干净、可验证的数据集,非常适合 RL 微调。这种细致的过滤确保了训练过程中的奖励能够真正反映正确性,而不是偶然性或过度拟合。
DeepCoder-14B大规模强化学习:rLLM框架
评估代码不同于评估文本。您不能仅仅比较标记的相似性–您需要运行代码并测试其输出,最好是在边缘情况下测试数千次。这就是 DeepCoder 的开源 RL 引擎 rLLM 的用武之地。
以下是 rLLM 脱颖而出的原因:
- 基于 verl 框架构建(将端到端训练时间缩短达 2 倍),这是一个专为代码设计的高效训练引擎
- 每分钟可运行 1,000 多个单元测试
- 使用 100 多个并行沙箱同时评估提交的测试结果
- 同时支持
- 共同代码解释器(便宜、快速,0.03 美元/问题)
- 本地沙盒镜像 LiveCodeBench,以实现可重复性
这种基础设施不仅速度快,而且使大规模、可验证的 RL 培训变得切实可行。没有手忙脚乱,没有近似值;真实的代码、真实的测试、真实的结果。
想试试吗?请访问代码仓库:github.com/agentica-project/rllm
这样就产生了一个包含 24,000 个编码问题的干净、可验证的数据集,非常适合 RL 微调。这种细致的过滤确保了训练过程中的奖励能够真正反映正确性,而不是偶然性或过度拟合。
亲身体验DeepCoder
虽然 DeepCoder 的性能指标令人印象深刻,但它对人工智能社区的真正价值在于其可访问性和可重复性。本节将介绍使用这一创新模型的实际操作,从初始设置到高级训练配置。
第 1 步:设置环境
DeepCoder 的开发团队针对 Python 3.10 对代码库进行了优化,确保稳定性的同时充分利用现代语言的特性。安装过程从创建专用的 Conda 环境开始:
conda create -n rllm python=3.10 -y conda activate rllm
导航到 rllm 目录后,你需要安装 verl 强化学习框架和主要包:
cd rllm pip install -e ./verl pip install -e .
这种安装模式反映了模块化架构,verl 作为专门的 DeepCoder-14B 强化学习引擎,为其令人印象深刻的代码生成能力提供动力。
第 2 步:准备训练数据
DeepCoder 的优势之一在于其精心策划的数据集。存储库既提供原始训练数据,也提供预处理脚本,以便将其转换为优化的训练格式。
要开始使用这些数据,请:
# First, download the curated datasets from GDrive python scripts/data/download_datasets.py # Then generate optimized parquet files for training python scripts/data/deepcoder_dataset.py # For DeepCoder # or python scripts/data/deepscaler_dataset.py # For DeepScaleR
这些预处理步骤实施了前面提到的严格数据质量控制,确保所有代码示例符合 DeepCoder-14B 强化学习的严格要求。
第 3 步:不同规模的训练选项
DeepCoder 灵活的训练架构可容纳各种计算资源,使其既适用于个人研究人员,也适用于拥有大量基础设施的大型团队。
针对个人研究人员
能够使用单台高性能机器的研究人员可以从以下方面开始训练:
export MODEL_PATH="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"./scripts/deepcoder/train/file.sh --model $MODEL_PATH
这种单节点配置为试验框架或针对特定领域进行微调提供了一个绝佳的切入点。
针对研究团队
DeepCoder 的分布式训练功能可让大型实验受益匪浅。该配置使用 Ray 来协调多台机器上的训练:
- 头部节点必须初始化 Ray 集群:
export VLLM_ATTENTION_BACKEND=XFORMERSray start --head - 然后,工作节点将连接到该协调器:
export VLLM_ATTENTION_BACKEND=XFORMERSray start --address=[HEAD_NODE_ADDRESS] (输出 VLLM_ATTENTION_BACKEND=XFORMERSray 启动 --head)。 - 集群准备就绪后,就可以启动训练:
./scripts/deepcoder/train/file.sh --model [CHECKPOINT_PATH] 。
这种可扩展的方法有助于实现 DeepCoder 的突破性性能,使团队能够有效地在更长的上下文长度和更大的数据集上进行训练。
第 4 步:严格的评估框架
DeepCoder 的性能声明由一个全面的评估框架提供支持,该框架可自动运行多个 vLLM 实例来测试模型的能力:
./scripts/eval/eval_model.sh --model [CHECKPOINT_PATH] \ --datasets [DATASET1] [DATASET2] \ --output-dir [OUTPUT_DIR] \ --n [N_PASSES] \ --tp [TENSOR_PARALLEL_SIZE] \ --max-length [MAX_CONTEXT_LENGTH]
这种评估方法与 LiveCodeBench 方法如出一辙,可确保报告的指标准确反映具有挑战性的编码任务的实际性能。
DeepCoder-14B 上机性能
在本节中,我们将探讨 DeepCoder-14B 能否以清晰和初学者友好的方式解释基本编程概念。
任务:解释编程概念
让我们使用 DeepCoder-14B 来解释哈希表的工作原理,并看看它能否生成一个 Python 示例。
代码:
response = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "Explain how a hash table works with an example in Python."
}
]
)
print(response['choices'][0]['message']['content'])
点评:
DeepCoder-14B 对散列表的功能进行了深思熟虑、循序渐进的概念分解,令人印象深刻。以下是其中的亮点:
- 个性化推理:回答的感觉就像一个初学者在大声讲述这个概念,这为解释增添了亲切感和教育性。
- 详细的理论:涵盖了散列、碰撞、链式、开放寻址等关键概念,以及在 Python 中通过字典实现这些概念的现实世界。
- 结构化方法:该模型没有立即跳入代码,而是列出了逻辑和设计步骤,如创建数组、定义哈希函数和处理碰撞。
- 缺少代码块:虽然它承诺用 Python 演示一个简单的哈希表,但代码片段并未包含在此输出中。要获得完整的答案,可以提示它“继续 Python 代码示例”。
推理性能说明:虽然模型输出的概念性很强,但延迟却非常高(总耗时约 11 分钟),这表明 DeepCoder-14B 可能最适合内容生成、辅导或文档等非实时应用。
DeepCoder-14B与o3-mini和o1:性能比较
在本节中,我们将比较 DeepCoder-14B 与 OpenAI 的 o1 和 03-mini 在代码生成和错误修复这两项常见编程任务中的表现。我们将给 DeepCoder-14B、o3-mini(用 Phi-2 模拟)和 o1(用 LLaMA-2 7B 模拟)分配同样的两项任务,看看模型的大小和设计如何影响代码质量、解释深度和推理能力。从生成一个简单函数到识别递归代码中的逻辑错误,这种比较将让我们更清楚地了解大型模型的真正优势和小型模型的优势。
任务 1:代码生成工具比较 – DeepCoder vs o3-mini (Phi-2)
让我们使用 DeepCoder-14B 生成一个查找 1 到 100 之间所有素数的 Python 函数,并将其响应与 o3-mini 进行比较。
DeepCoder-14B 生成代码:
response = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "Write a Python function to find prime numbers between 1 and 100."
}
]
)
print("DeepCoder Output:\n", response['choices'][0]['message']['content'])
Phi-2 (Simulating o3-mini) 生成代码:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", device_map="auto")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer
prompt = "Write a Python function to find prime numbers between 1 and 100."
output = pipe(prompt, max_new_tokens=150)[0]["generated_text"]
print("Phi-2 Output:\n", output)
评价:
DeepCoder-14B 深入浅出、循序渐进地剖析了寻找质数背后的逻辑,模仿了初学者推理问题的方式。虽然它很有见地,但并不返回实际代码,这限制了它在直接执行方面的实用性。相比之下,Phi-2 (o3-mini) 不需要任何解释,就能提供一个简洁、正确的 Python 函数,快速、高效,随时可以运行。DeepCoder 更适合深度教学,而 Phi-2 则更擅长实用的编码速度和清晰度。
任务 2:错误修复与推理 – DeepCoder vs o1(LLaMA-2 7B)
现在,让我们用一项经典的调试任务来挑战 DeepCoder-14B。我们将向它提供一个有错误的递归阶乘函数,要求它修复代码并解释出错的原因。然后,我们将把同样的任务交给 OpenAI 的 o1 模型(由 LLaMA-27B 模拟),并比较它们的反应。
错误代码:
buggy_code = """ def factorial(n): if n == 0: return 0 else: return n * factorial(n-1) """
DeepCoder-14B:
response = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": f"This code has a bug. Fix it and explain the correction:\n{buggy_code}"
}
]
)
print("DeepCoder Output:\n", response['choices'][0]['message']['content'])
LLaMA-2 7B (simulating o1):
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", device_map="auto")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "This code has a bug. Fix it and explain the correction:\n" + buggy_code
output = pipe(prompt, max_new_tokens=200)[0]["generated_text"]
print("LLaMA-2 Output:\n", output)
点评:
在这个任务中,DeepCoder-14B 和 o1(LLaMA-2 7B)都正确地发现了阶乘函数中的错误–认识到基例应该返回 1 而不是 0。DeepCoder-14B 通过逻辑推理,强调了错误的基例如何导致错误的结果,特别是 n=1 时,表现出很强的推理能力。
然而,它的输出存在一个关键缺陷:重复循环“Wait, no”,这降低了可读性,并使响应感觉不稳定。相比之下,o1 的响应简洁、干净、正确,通常包括固定代码和简要解释。虽然没有 DeepCoder 的推理深度,但 o1 的可靠性和清晰度使其更适合实际使用,尤其是在部署或教育环境中。
DeepCoder-14B的未来发展
虽然目前的成果主要集中在编码方面,但该团队计划
- 通过动态 NTK 缩放将上下文窗口扩展到 128K。
- 开发多模型推理能力。
- 为安全审计和遗留代码现代化创建专用变体。
这一版本标志着向高级人工智能编码工具民主化迈出了重要一步,它为研究人员和开发人员提供了
- 与专有模型性能相匹配的完整训练配方。
- 大规模可验证 RL 的基础设施。
- 未来程序合成开源进展的基线。
该模型的麻省理工学院许可证确保了商业和研究使用不受限制,促进了整个人工智能生态系统的创新。DeepCoder-14B 兼具极具竞争力的性能和完全的透明度,为开源人工智能编码模型的开发确立了新的标准。
DeepCoder-14B:访问和使用
DeepCoder 的一切都围绕着透明度和社区展开:
- 模型权重:通过 Hugging Face 公开提供
- 训练管道:通过 rLLM GitHub repo 共享
- 博客细分:官方概念文章
这使得它成为以下人员的绝佳资源
- 探索 RL 微调的研究人员
- 构建自定义编码代理的黑客和开发人员
- 展示真实世界中人工智能编码系统如何构建和测试的教育工作者
小结
在这个由封闭墙和黑盒模型主导的时代,DeepCoder-14B 是一股新鲜空气。它表明,开源人工智能编码模型可以扩展、竞争和创新,而无需躲在应用程序接口或付费墙后面。从上下文扩展到数学泛化,从经过验证的数据集到高速沙盒,DeepCoder 的一切都让人感到深思熟虑、用心良苦、社区至上。
希望改进编码工作流程的开发人员可以立即开始使用 DeepCoder。该模型在竞赛级编码任务上的出色表现使其适用于从自动代码补全到算法问题解决等各种应用。如果您正在构建人工智能辅助开发的未来,DeepCoder-14B 不仅值得一试,还可能成为您的新基准。













暂无评论内容