

从文本生成视频已经取得了长足的进步,但在制作较长的多场景故事时仍然会遇到障碍。虽然 Sora、Veo 和 Movie Gen 等扩散模型提高了视觉质量,但它们通常仅限于 20 秒以内的片段。真正的挑战是什么?语境。要从一段文字中生成一分钟的故事驱动型视频,需要模型处理成百上千个标记,同时保持叙事和视觉的连贯性。这正是英伟达™(NVIDIA®)、斯坦福大学、加州大学伯克利分校和其他机构的最新研究成果所要解决的问题,该研究引入了一种名为“Test-Time 训练”(TTT)的技术,以突破目前的限制。
长视频有什么问题?
Transformer,尤其是用于视频生成的 Transformer,依赖于自我注意机制。由于其计算成本为二次方,因此随着序列长度的增加,这种机制的扩展性很差。试图生成一个完整的、具有动态场景和一致角色的一分钟高分辨率视频,意味着要处理 30 多万个信息标记。这使得该模型效率低下,而且在长时间内往往不连贯。
一些团队试图通过使用 Mamba 或 DeltaNet 等递归神经网络(RNN)来规避这一问题,这些网络提供线性时间上下文处理功能。然而,这些模型将上下文压缩到固定大小的隐藏状态中,从而限制了表达能力。这就好比要把整部电影挤进一张明信片,有些细节根本放不下。
TTT(Test-Time Training)如何解决这个问题?
这篇论文提出的想法是,通过将 RNN 的隐藏状态转化为可训练的神经网络本身,使其更具表现力。具体来说,作者建议使用 TTT 层,即在处理输入序列时进行快速适应的小型双层 MLP。这些层在推理过程中使用自监督损失进行更新,这有助于它们动态地从视频不断变化的上下文中学习。
想象一下一个能在飞行过程中进行调整的模型:随着视频的展开,它的内部记忆会进行调整,以便更好地理解人物、动作和故事情节。这就是 TTT 所能实现的。

Source: One-Minute Video Generation with Test-Time Training
使用Test-Time训练的一分钟视频示例
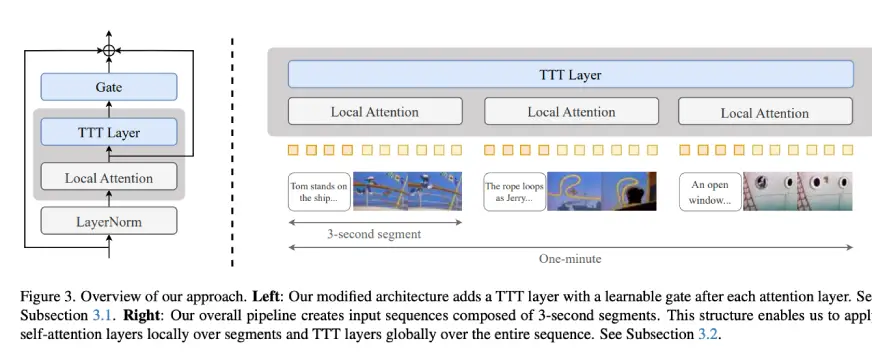
在预训练 Transformer 中添加 TTT 层
在预训练 Transformer 中添加 TTT 层,可使其生成的一分钟视频具有很强的时间一致性和运动平滑性。
提示:“Jerry snatches a wedge of cheese and races for his mousehole with Tom in pursuit. He slips inside just in time, leaving Tom to crash into the wall. Safe and cozy, Jerry enjoys his prize at a tiny table, happily nibbling as the scene fades to black.”
基准比较
根据人类评估的 Elo 分数,TTT-MLP 在时间一致性、运动流畅度和整体美观度方面均优于所有其他基线。
提示:“Tom is happily eating an apple pie at the kitchen table. Jerry looks longingly wishing he had some. Jerry goes outside the front door of the house and rings the doorbell. While Tom comes to open the door, Jerry runs around the back to the kitchen. Jerry steals Tom’s apple pie. Jerry runs to his mousehole carrying the pie, while Tom is chasing him. Just as Tom is about to catch Jerry, he makes it through the mouse hole and Tom slams into the wall.”
局限性
生成的一分钟视频作为概念验证具有明显的潜力,但仍包含明显的人工痕迹。
它是如何工作的?
该系统从一个预先训练好的 Diffusion Transformer 模型 CogVideo-X 5B 开始,该模型以前只能生成 3 秒钟的片段。研究人员在模型中插入了 TTT 层,并对其进行了训练(连同局部注意力区块),以处理更长的序列。
为了控制成本,自我注意力被限制在 3 秒钟的短片段上,而 TTT 层则负责理解这些片段中的全局叙事。该架构还包括门控机制,以确保 TTT 层在早期训练中不会降低性能。
Source: One-Minute Video Generation with Test-Time Training
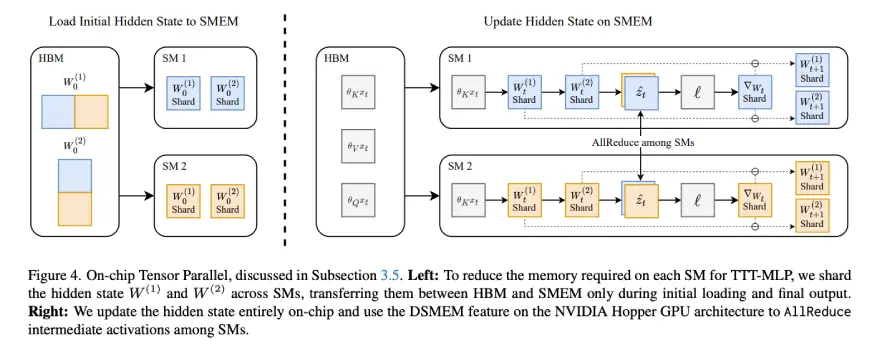
它们通过双向处理序列和将视频分割成有注释的场景,进一步增强了训练效果。例如,使用故事板格式详细描述每个 3 秒钟的片段、背景、人物位置、摄像机角度和动作。
Source: One-Minute Video Generation with Test-Time Training
数据集:Tom & Jerry
为了使研究立足于一个一致的、易于理解的视觉领域,研究小组从超过 7 小时的经典《汤姆和杰瑞》动画片中整理出一个数据集。这些数据被分解成不同的场景,并精细地注释成 3 秒钟的片段。通过专注于动画片数据,研究人员避免了照相逼真的复杂性,而专注于叙事的连贯性和运动动态。
人类注释员为每个片段撰写描述性段落,确保模型有丰富、结构化的输入可供学习。这样还可以进行多阶段训练–首先是 3 秒钟的片段,然后逐步训练长达 63 秒的较长序列。

Source: One-Minute Video Generation with Test-Time Training
性能:它真的有用吗?
是的,而且令人印象深刻。与 Mamba 2、Gated DeltaNet 和滑动窗口注意力等领先基准相比,TTT-MLP 模型在 100 个视频的人工评估中平均超出它们 34 个 Elo 点。
评估考虑了以下因素
- 文本对齐:视频在多大程度上遵循了提示
- 动作自然度:人物动作的逼真度
- 美观:灯光、色彩和视觉吸引力
- 时间一致性:跨场景的视觉连贯性
TTT-MLP 在动作和场景一致性方面表现尤为突出,它能在动态动作中保持逻辑连续性–这是其他模型难以做到的。
缺陷与局限
尽管结果令人满意,但仍存在人工痕迹。光照可能会不一致地变化,或者运动可能看起来很漂浮(例如奶酪不自然地悬停)。这些问题可能与基础模型 CogVideo-X 的局限性有关。另一个瓶颈是效率。虽然 TTT-MLP 比完全自注意模型快得多(速度提高了 2.5 倍),但它仍然比 Gated DeltaNet 等更精简的 RNN 方法要慢。尽管如此,TTT 只需要微调,而不需要从头开始训练,这使得它在许多使用案例中更加实用。
该方法的独特之处
- 富有表现力的内存:TTT 将 RNN 的隐藏状态转化为可训练网络,使其比固定大小的矩阵更具表现力。
- 适应性:TTT 层在推理过程中进行学习和调整,使其能够实时响应正在展开的视频。
- 可扩展性:只要有足够的资源,这种方法就能扩展到更长、更复杂的视频故事。
- 实用微调:研究人员只对 TTT 层和门进行微调,从而保持了训练的轻量和高效。
未来方向
研究小组指出了几个扩展机会:
- 优化 TTT 内核,加快推理速度
- 尝试使用更大或不同的骨干模型
- 探索更复杂的故事情节和领域
- 使用基于变换器的隐藏状态,而不是 MLP,以获得更强的表现力
TTT 视频生成器 vs MoCha vs Goku vs OmniHuman1 vs DreamActor-M1
下表解释了该模型与其他流行的视频生成模型之间的区别:
| 模型 | 核心焦点 | 输入类型 | 关键特征 | 与 TTT 的区别 |
|---|---|---|---|---|
| TTT (Test-Time Training) | 生成动态适应的长视频 | 文本故事板 | – 在推理过程中进行调整 – 可处理 60 秒以上的视频 – 连贯的多场景故事 |
专为长视频设计;在生成过程中更新内部状态,以确保叙事的一致性 |
| MoCha | 生成会说话的字符 | 文本 + 语音 | – 无关键点或参考图像 – 语音驱动的全身动画 |
侧重于角色对话和表情,而非全场景叙事视频 |
| Goku | 生成高质量视频和图像 | 文本、图像 | – 整流Transformer – 支持多模态输入 |
针对质量和训练速度进行了优化;并非专为长篇叙事而设计 |
| OmniHuman1 | 逼真的人体动画 | 图像 + 音频 + 文本 | – 多种调节信号 – 高清头像 |
创建栩栩如生的人物;不模拟长序列或动态场景转换 |
| DreamActor-M1 | 图像到动画(面部/身体) | 图像 + 驾驶视频 | – 整体动作模仿 – 高度的帧一致性 |
为静态图像制作动画;不使用文本或处理逐个场景的故事生成 |
推荐阅读
- MoCha:Meta 在会说话的角色合成方面的电影级飞跃
- ByteDance 的 DreamActor-M1 将照片转换成视频
小结
Test-Time Training 为解决长语境视频生成问题提供了一个令人着迷的新视角。通过让模型在推理过程中学习和适应,它弥补了讲故事过程中的一个重要缺陷,在这个领域中,连续性、情感和节奏与视觉保真度同样重要。
无论您是生成式人工智能的研究人员、创意技术专家,还是对人工智能生成媒体的下一步发展充满好奇的产品领导者,这项工作都是指向未来动态、连贯的文本视频合成的路标。













暂无评论内容