

你知道在过去,我们如何使用简单的字数技巧来表示文本吗?从那时起,我们已经走过了漫长的道路。现在,当我们谈论嵌入式技术的发展时,我们指的是数字快照,它不仅能捕捉出现的字词,还能捕捉它们的真正含义,它们在上下文中的相互关系,甚至它们与图像和其他媒体的联系。从能理解你意图的搜索引擎到似乎能读懂你心思的推荐系统,嵌入技术为一切提供了动力。它们也是尖端人工智能和机器学习应用的核心。因此,让我们来回顾一下从原始计数到语义向量的演变过程,探索每种方法的工作原理、带来的好处以及不足之处。
Source: Link
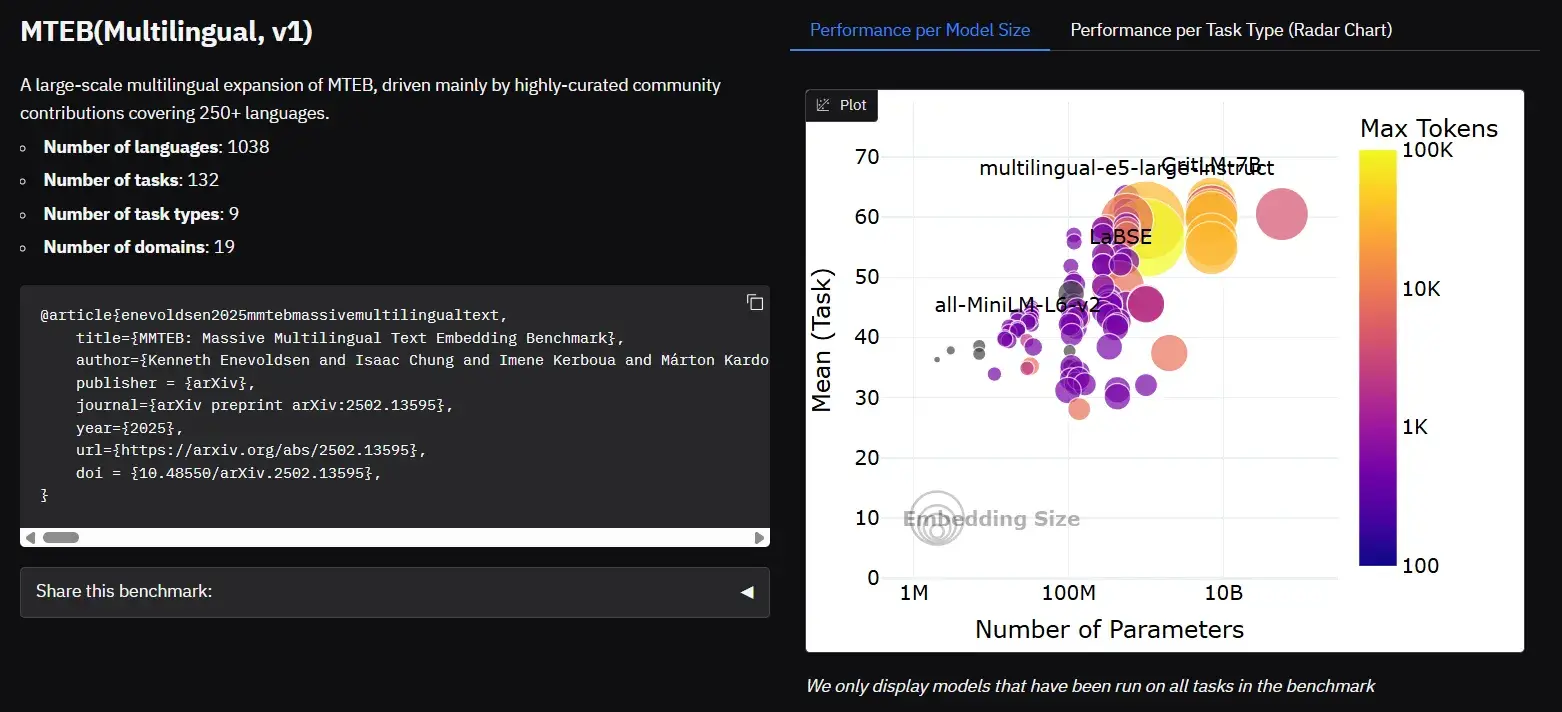
MTEB排行榜中的嵌入排名
大多数现代 LLM 都会生成嵌入词,作为其架构的中间输出。这些嵌入可以针对各种下游任务进行提取和微调,从而使基于 LLM 的嵌入成为当今最通用的工具之一。
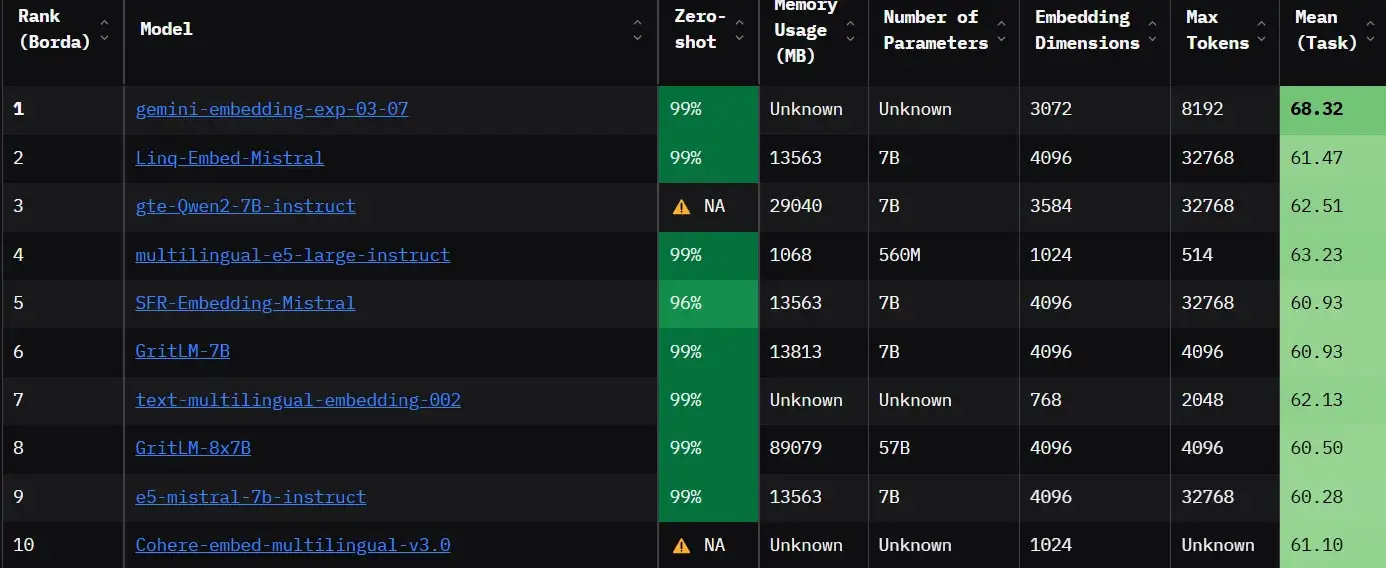
为了跟上快速发展的形势,Hugging Face 等平台引入了大量文本嵌入基准(MTEB)排行榜等资源。该排行榜根据嵌入模型在分类、聚类、检索等各种任务中的表现进行排名。这将极大地帮助从业人员确定最适合其使用案例的模型。
有了对排行榜的深入了解,让我们卷起袖子,深入研究矢量化工具箱–计数矢量、TF-IDF 和其他经典方法,它们仍然是当今复杂嵌入模型的重要组成部分。
有了这些对排行榜的深入了解,让我们卷起袖子,深入研究矢量化工具箱–计数矢量、TF-IDF 和其他经典方法,它们仍然是当今复杂嵌入式的重要组成部分。
1. 计数矢量化
计数矢量化是表示文本的最简单技术之一。它的出现源于将原始文本转换成数字形式以便机器学习模型处理的需要。在这种方法中,每篇文档都被转换成一个向量,反映其中出现的每个单词的计数。这种简单明了的方法为更复杂的表示法奠定了基础,在对可解释性要求较高的情况下仍然非常有用。
工作原理
- 机制:
- 首先将文本语料标记化为单词。从所有独特的标记词中建立词汇表。
- 每个文档被表示为一个向量,其中每个维度都对应于词汇表中该单词各自的向量。
- 每个维度的值只是文档中某个词的频率或计数。
- 举例说明: 对于词汇表 [“apple”、“banana”、“cherry”],文档 “apple apple cherry”变为 [2, 0, 1]。
- 更多详情: 计数矢量化是许多其他方法的基础。它的简单性并不能捕捉到任何上下文或语义信息,但它仍然是许多 NLP 流程中必不可少的预处理步骤。
代码实现
from sklearn.feature_extraction.text import CountVectorizer import pandas as pd # Sample text documents with repeated words documents = [ "Natural Language Processing is fun and natural natural natural", "I really love love love Natural Language Processing Processing Processing", "Machine Learning is a part of AI AI AI AI", "AI and NLP NLP NLP are closely related related" ] # Initialize CountVectorizer vectorizer = CountVectorizer() # Fit and transform the text data X = vectorizer.fit_transform(documents) # Get feature names (unique words) feature_names = vectorizer.get_feature_names_out() # Convert to DataFrame for better visualization df = pd.DataFrame(X.toarray(), columns=feature_names) # Print the matrix print(df)
输出:

优点
- 简单易懂:易于实施和理解。
- 确定性:产生固定的表示形式,易于分析。
缺点
- 高维度和稀疏性:向量通常很大,且大部分为零,导致效率低下。
- 缺乏语义语境:无法捕捉词与词之间的意义或关系。
2. One-Hot编码
One-Hot 编码是最早将单词表示为向量的方法之一。它与 20 世纪 50 和 60 年代早期的数字计算技术一起发展,将单词等分类数据转换为二进制向量。每个单词都有唯一的表示形式,确保没有两个单词有相似的表示形式,但这样做的代价是无法捕捉语义的相似性。
工作原理
- 机制:
- 词汇表中的每个词都会被分配一个向量,其长度等于词汇表的大小。
- 在每个向量中,所有元素都是 0,只有该词对应位置上的一个 1 除外。
- 举例说明:词汇表[“apple”、“banana”、“cherry”]中的单词 “banana”表示为[0, 1, 0]。
- 其他细节:单热向量是完全正交的,这意味着两个不同单词之间的余弦相似度为零。这种方法简单明了,但无法捕捉到任何相似性(例如,“apple”和 “orange”与 “apple”和 “car”的相似性相同)。
代码实现
from sklearn.feature_extraction.text import CountVectorizer import pandas as pd # Sample text documents documents = [ "Natural Language Processing is fun and natural natural natural", "I really love love love Natural Language Processing Processing Processing", "Machine Learning is a part of AI AI AI AI", "AI and NLP NLP NLP are closely related related" ] # Initialize CountVectorizer with binary=True for One-Hot Encoding vectorizer = CountVectorizer(binary=True) # Fit and transform the text data X = vectorizer.fit_transform(documents) # Get feature names (unique words) feature_names = vectorizer.get_feature_names_out() # Convert to DataFrame for better visualization df = pd.DataFrame(X.toarray(), columns=feature_names) # Print the one-hot encoded matrix print(df)
输出:

因此,基本上可以看出 Count Vectorizer 和 One Hot Encoding 之间的区别。Count Vectorizer 计算的是某个单词在句子中出现的次数,而 One Hot Encoding 则是将某个单词在某个句子/文档中出现的次数标为 1。
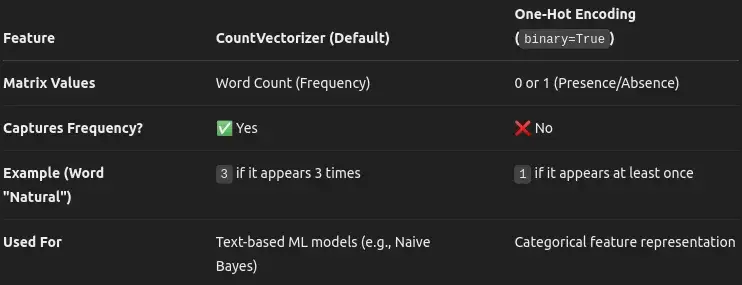
何时使用?
- 当一个词出现的次数很重要时(如垃圾邮件检测、文档相似性),请使用 CountVectorizer。
- 当您只关心一个词是否至少出现过一次时,请使用 One-Hot Encoding(例如,用于 ML 模型的分类特征编码)。
优点
- 清晰独特:每个词都有一个独特且不重叠的表示法
- 简单:易于实现,对小型词汇表的计算开销最小。
缺点
- 词汇量大时效率低:向量变得非常高维和稀疏。
- 无语义相似性:不允许词与词之间存在任何关系;所有非相同词的距离都相同。
3. TF-IDF(词频-反向文档频率)
TF-IDF 是为了改进原始计数方法而开发的,它通过计算单词出现次数,并根据单词在语料库中的整体重要性对其进行权衡。TF-IDF 于 20 世纪 70 年代初推出,是信息检索系统和文本挖掘应用的基石。它有助于突出单个文档中重要的词汇,同时淡化所有文档中常见的词汇。
工作原理
- 机制:
- 词频 (TF):衡量一个词在文档中出现的频率。
- 反向文档频率 (IDF):通过考虑一个词在所有文档中的常见或罕见程度来衡量其重要性。
- 最终的 TF-IDF 分数是 TF 和 IDF 的乘积。

Source: Link
- 举例说明:像 “the”这样的常用词得分较低,而较为独特的词得分较高,因此在文档分析中比较突出。因此,在 NLP 任务中,我们通常会省略频繁出现的词语,这些词语也被称为 Stopwords。
- 其他细节:TF-IDF 将原始频率计数转化为一种能有效区分重要关键词和常用词的方法。它已成为搜索引擎和文档聚类的标准方法。
代码实现
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
# Sample short sentences
documents = [
"cat sits here",
"dog barks loud",
"cat barks loud"
]
# Initialize TfidfVectorizer to get both TF and IDF
vectorizer = TfidfVectorizer()
# Fit and transform the text data
X = vectorizer.fit_transform(documents)
# Extract feature names (unique words)
feature_names = vectorizer.get_feature_names_out()
# Get TF matrix (raw term frequencies)
tf_matrix = X.toarray()
# Compute IDF values manually
idf_values = vectorizer.idf_
# Compute TF-IDF manually (TF * IDF)
tfidf_matrix = tf_matrix * idf_values
# Convert to DataFrames for better visualization
df_tf = pd.DataFrame(tf_matrix, columns=feature_names)
df_idf = pd.DataFrame([idf_values], columns=feature_names)
df_tfidf = pd.DataFrame(tfidf_matrix, columns=feature_names)
# Print tables
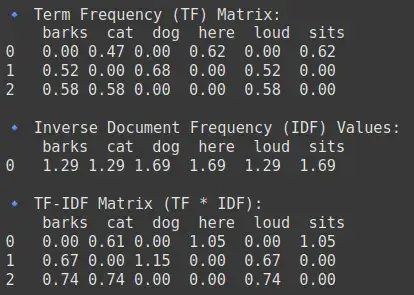
print("\n🔹 Term Frequency (TF) Matrix:\n", df_tf)
print("\n🔹 Inverse Document Frequency (IDF) Values:\n", df_idf)
print("\n🔹 TF-IDF Matrix (TF * IDF):\n", df_tfidf)
输出:
优点
- 增强单词重要性:强调特定内容的词语。
- 降低维度:过滤掉附加值低的普通词语。
缺点
- 表示稀疏:尽管进行了加权,但得到的向量仍然稀疏。
- 缺乏语境:无法捕捉词序或更深层的语义关系。
4. Okapi BM25
Okapi BM25 开发于 20 世纪 90 年代,是一种概率模型,主要用于信息检索系统中的文档排序,而非嵌入方法本身。BM25 是 TF-IDF 的增强版,常用于搜索引擎和信息检索。它在 TF-IDF 的基础上进行了改进,考虑了文档长度归一化和词频饱和(即重复词的收益递减)。
工作原理
- 机制:
- 概率框架:该框架根据查询词频来估算文档的相关性,并根据文档长度进行调整。
- 使用参数来控制词频的影响,并抑制极高计数的影响。
在此,我们将研究 BM25 评分机制:

Source – Link

Source – Link
BM25 引入了两个参数,即 k1 和 b,可分别对词频饱和度和长度归一化进行微调。这些参数对于优化 BM25 算法在各种搜索环境下的性能至关重要。
- 例如:BM25 在根据文档长度进行调整的同时,会给包含中等频率的罕见查询词的文档分配更高的相关性分数,反之亦然。
- 其他细节:虽然 BM25 不会产生向量嵌入,但它改进了 TF-IDF 在文档排序方面的不足,从而对文本检索系统产生了深远的影响。
代码实现
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
# Sample documents
documents = [
"cat sits here",
"dog barks loud",
"cat barks loud"
]
# Compute Term Frequency (TF) using CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
tf_matrix = X.toarray()
feature_names = vectorizer.get_feature_names_out()
# Compute Inverse Document Frequency (IDF) for BM25
N = len(documents) # Total number of documents
df = np.sum(tf_matrix > 0, axis=0) # Document Frequency (DF) for each term
idf = np.log((N - df + 0.5) / (df + 0.5) + 1) # BM25 IDF formula
# Compute BM25 scores
k1 = 1.5 # Smoothing parameter
b = 0.75 # Length normalization parameter
avgdl = np.mean([len(doc.split()) for doc in documents]) # Average document length
doc_lengths = np.array([len(doc.split()) for doc in documents])
bm25_matrix = np.zeros_like(tf_matrix, dtype=np.float64)
for i in range(N): # For each document
for j in range(len(feature_names)): # For each term
term_freq = tf_matrix[i, j]
num = term_freq * (k1 + 1)
denom = term_freq + k1 * (1 - b + b * (doc_lengths[i] / avgdl))
bm25_matrix[i, j] = idf[j] * (num / denom)
# Convert to DataFrame for better visualization
df_tf = pd.DataFrame(tf_matrix, columns=feature_names)
df_idf = pd.DataFrame([idf], columns=feature_names)
df_bm25 = pd.DataFrame(bm25_matrix, columns=feature_names)
# Display the results
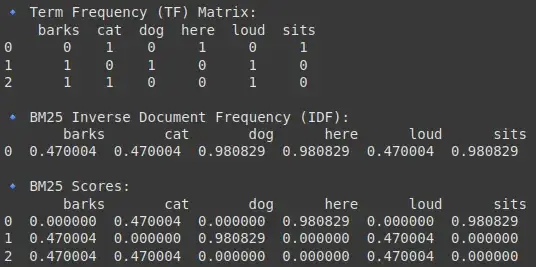
print("\n🔹 Term Frequency (TF) Matrix:\n", df_tf)
print("\n🔹 BM25 Inverse Document Frequency (IDF):\n", df_idf)
print("\n🔹 BM25 Scores:\n", df_bm25)
输出:
代码执行(信息检索)
!pip install bm25s
import bm25s
# Create your corpus here
corpus = [
"a cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
"a fish is a creature that lives in water and swims",
]
# Create the BM25 model and index the corpus
retriever = bm25s.BM25(corpus=corpus)
retriever.index(bm25s.tokenize(corpus))
# Query the corpus and get top-k results
query = "does the fish purr like a cat?"
results, scores = retriever.retrieve(bm25s.tokenize(query), k=2)
# Let's see what we got!
doc, score = results[0, 0], scores[0, 0]
print(f"Rank {i+1} (score: {score:.2f}): {doc}")
输出:

优势
- 改进相关性排名:更好地处理文档长度和术语饱和度。
- 广泛采用:许多现代搜索引擎和 IR 系统的标准配置。
缺点
- 不是真正的嵌入:它对文档进行评分,而不是产生连续的向量空间表示。
- 参数敏感性:需要仔细调整才能达到最佳性能。
5. Word2Vec(CBOW和Skip-gram)
Word2Vec 由谷歌于 2013 年推出,它通过学习单词的密集、低维向量表示,彻底改变了 NLP。它超越了计数和加权,通过训练浅层神经网络来捕捉基于单词上下文的语义和句法关系。Word2Vec 有两种类型: 连续词袋 (CBOW) 和跳格。
工作原理
- CBOW(连续词袋):
- 机制:根据周围的语境词预测目标词。
- 过程:提取多个上下文单词(忽略顺序),并学习预测中心词。
- 跳格
- 机制:使用目标词预测其周围的语境词。
- 过程:通过关注上下文,对学习罕见词的表征尤为有效。


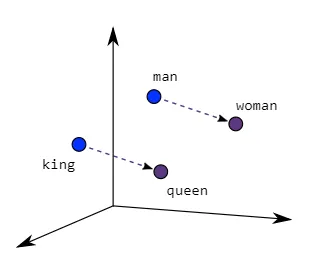
- 其他细节: 这两种架构都使用了带有一个隐藏层的神经网络,并采用了负采样或分层软最大值等优化技巧来管理计算复杂性。由此产生的嵌入结果可以捕捉到细微的语义关系,例如,“king”减去“man”再加上“woman”就近似于“queen”。
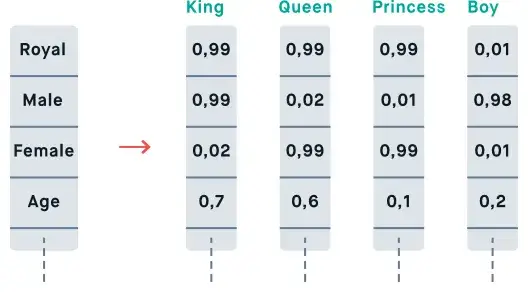
Source: Link
代码执行
!pip install numpy==1.24.3
from gensim.models import Word2Vec
import networkx as nx
import matplotlib.pyplot as plt
# Sample corpus
sentences = [
["I", "love", "deep", "learning"],
["Natural", "language", "processing", "is", "fun"],
["Word2Vec", "is", "a", "great", "tool"],
["AI", "is", "the", "future"],
]
# Train Word2Vec models
cbow_model = Word2Vec(sentences, vector_size=10, window=2, min_count=1, sg=0) # CBOW
skipgram_model = Word2Vec(sentences, vector_size=10, window=2, min_count=1, sg=1) # Skip-gram
# Get word vectors
word = "is"
print(f"CBOW Vector for '{word}':\n", cbow_model.wv[word])
print(f"\nSkip-gram Vector for '{word}':\n", skipgram_model.wv[word])
# Get most similar words
print("\n🔹 CBOW Most Similar Words:", cbow_model.wv.most_similar(word))
print("\n🔹 Skip-gram Most Similar Words:", skipgram_model.wv.most_similar(word))
输出:

可视化 CBOW 和 Skip-gram:
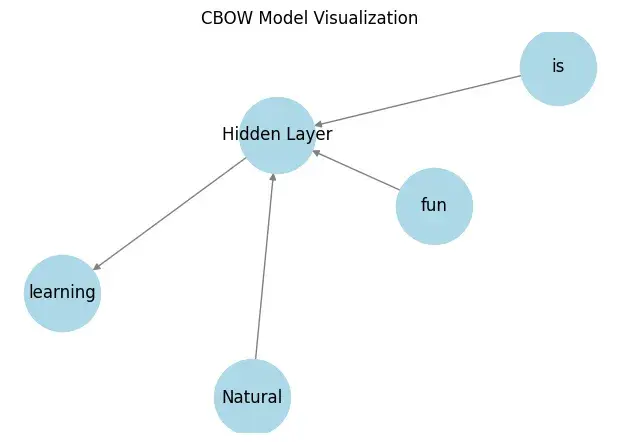
def visualize_cbow():
G = nx.DiGraph()
# Nodes
context_words = ["Natural", "is", "fun"]
target_word = "learning"
for word in context_words:
G.add_edge(word, "Hidden Layer")
G.add_edge("Hidden Layer", target_word)
# Draw the network
pos = nx.spring_layout(G)
plt.figure(figsize=(6, 4))
nx.draw(G, pos, with_labels=True, node_size=3000, node_color="lightblue", edge_color="gray")
plt.title("CBOW Model Visualization")
plt.show()
visualize_cbow()
输出:
def visualize_skipgram():
G = nx.DiGraph()
# Nodes
target_word = "learning"
context_words = ["Natural", "is", "fun"]
G.add_edge(target_word, "Hidden Layer")
for word in context_words:
G.add_edge("Hidden Layer", word)
# Draw the network
pos = nx.spring_layout(G)
plt.figure(figsize=(6, 4))
nx.draw(G, pos, with_labels=True, node_size=3000, node_color="lightgreen", edge_color="gray")
plt.title("Skip-gram Model Visualization")
plt.show()
visualize_skipgram()
输出:
优点
- 语义丰富:学习单词之间有意义的关系
- 高效训练:可相对快速地在大型语料库中进行训练。
- 密集表示:使用低维度的连续向量,便于下游处理。
缺点
- 静态表示:无论上下文如何,每个词只提供一种嵌入。
- 语境限制:无法区分在不同语境中具有不同含义的多义词。
6. GloVe(词汇表示的全局向量)
GloVe 于 2014 年在斯坦福大学开发,以 Word2Vec 的理念为基础,将全局共现统计与本地上下文信息相结合。它旨在生成能捕捉语料库整体统计信息的词语嵌入,从而提高不同语境下的一致性。
工作原理
- 机制:
- 共现矩阵:构建一个矩阵,记录词对在整个语料库中出现的频率。
这种共现矩阵逻辑也广泛应用于计算机视觉领域,尤其是在 GLCM(灰度共现矩阵)主题下。这是一种用于图像处理和计算机视觉纹理分析的统计方法,它考虑了像素之间的空间关系。
- 共现矩阵:构建一个矩阵,记录词对在整个语料库中出现的频率。
![图片[1]-14种定义嵌入演进的强大技术-极客小站](https://www.wpwpp.com/wp-content/uploads/2025/04/20-image28.webp)
-
-
- 矩阵因式分解:对该矩阵进行因式分解,从而得出能捕捉全局统计信息的词向量。
- 其他细节:与 Word2Vec 的纯预测模型不同,GloVe 的方法允许模型学习单词共现率,一些研究发现这种方法在捕捉语义相似性和类比性方面更为稳健。
-
代码实施
import numpy as np
# Load pre-trained GloVe embeddings
glove_model = api.load("glove-wiki-gigaword-50") # You can use "glove-twitter-25", "glove-wiki-gigaword-100", etc.
# Example words
word = "king"
print(f"🔹 Vector representation for '{word}':\n", glove_model[word])
# Find similar words
similar_words = glove_model.most_similar(word, topn=5)
print("\n🔹 Words similar to 'king':", similar_words)
word1 = "king"
word2 = "queen"
similarity = glove_model.similarity(word1, word2)
print(f"🔹 Similarity between '{word1}' and '{word2}': {similarity:.4f}")
输出:


这张图片将帮助您了解这种相似性在绘制时的样子:
优点
- 全球语境整合: 使用整个语料库的统计数据来提高代表性。
- 稳定性: 通常能在不同语境中产生更一致的嵌入。
缺点
- 资源需求大: 构建和因式分解大型矩阵的计算成本可能很高。
- 静态性: 与 Word2Vec 类似,它不能生成与上下文相关的嵌入词。
GloVe 从词共现矩阵中学习嵌入。
7. FastText
FastText 由 Facebook 于 2016 年发布,通过纳入子词(字符 n-gram)信息对 Word2Vec 进行了扩展。这一创新通过将单词分解为更小的单元,从而捕捉内部结构,帮助模型处理罕见单词和形态丰富的语言。
工作原理
- 机制:
- 子词建模:将每个单词表示为其字符 n-gram 向量的总和。
- 嵌入学习:训练一个模型,利用这些子词向量生成最终的词嵌入。
- 其他细节:这种方法对于具有丰富词形的语言和处理词汇表以外的单词特别有用。通过分解单词,FastText 可以更好地概括类似的单词形式和拼写错误。
代码实现
import gensim.downloader as api
fasttext_model = api.load("fasttext-wiki-news-subwords-300")
# Example word
word = "king"
print(f"🔹 Vector representation for '{word}':\n", fasttext_model[word])
# Find similar words
similar_words = fasttext_model.most_similar(word, topn=5)
print("\n🔹 Words similar to 'king':", similar_words)
word1 = "king"
word2 = "queen"
similarity = fasttext_model.similarity(word1, word2)
print(f"🔹 Similarity between '{word1}' and '{word2}': {similarity:.4f}")
输出:


优点
- 处理 OOV(词汇表外)单词:当单词不常见或未见过时,可提高性能。可以说,测试数据集中有一些标签在我们的训练数据集中并不存在。
- 形态意识:捕捉词语的内部结构。
缺点
- 复杂性增加:包含子词信息会增加计算开销。
- 仍然是静态或固定的:尽管 FastText 有所改进,但它不会根据句子的上下文调整嵌入。
8. Doc2Vec
Doc2Vec 将 Word2Vec 的理念扩展到更大的文本体,如句子、段落或整个文档。Doc2Vec 于 2014 年推出,它为可变长度的文本提供了一种获得固定长度向量表示的方法,从而实现更有效的文档分类、聚类和检索。
工作原理
- 机制 :
- 分布式内存(DM)模型:通过添加一个独特的文档向量来增强 Word2Vec 架构,该向量与上下文单词一起预测目标单词。
- 分布式词袋 (DBOW) 模型:通过预测从文档中随机抽取的单词来学习文档向量。
- 其他细节:这些模型学习文档级嵌入,以捕捉文本的整体语义内容。对于需要了解整个文档的结构和主题的任务,这些模型尤其有用。
代码实现
import gensim
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
import nltk
nltk.download('punkt_tab')
# Sample documents
documents = [
"Machine learning is amazing",
"Natural language processing enables AI to understand text",
"Deep learning advances artificial intelligence",
"Word embeddings improve NLP tasks",
"Doc2Vec is an extension of Word2Vec"
]
# Tokenize and tag documents
tagged_data = [TaggedDocument(words=nltk.word_tokenize(doc.lower()), tags=[str(i)]) for i, doc in enumerate(documents)]
# Print tagged data
print(tagged_data)
# Define model parameters
model = Doc2Vec(vector_size=50, window=2, min_count=1, workers=4, epochs=100)
# Build vocabulary
model.build_vocab(tagged_data)
# Train the model
model.train(tagged_data, total_examples=model.corpus_count, epochs=model.epochs)
# Test a document by generating its vector
test_doc = "Artificial intelligence uses machine learning"
test_vector = model.infer_vector(nltk.word_tokenize(test_doc.lower()))
print(f"🔹 Vector representation of test document:\n{test_vector}")
# Find most similar documents to the test document
similar_docs = model.dv.most_similar([test_vector], topn=3)
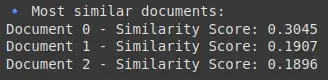
print("🔹 Most similar documents:")
for tag, score in similar_docs:
print(f"Document {tag} - Similarity Score: {score:.4f}")
输出:
优点
- 文档级表述:有效捕捉较大文本的主题和上下文信息。
- 用途广泛:适用于从推荐系统到聚类和摘要等各种任务。
缺点
- 训练敏感性:需要大量数据和仔细调整才能生成高质量的讲师向量。
- 静态嵌入:无论内容的内部变化如何,每份文档都用一个向量来表示。
9. InferSent
InferSent 由 Facebook 于 2017 年开发,旨在通过对自然语言推理(NLI)数据集的监督学习生成高质量的句子嵌入。它旨在捕捉句子层面的语义细微差别,使其对语义相似性和文本蕴含等任务非常有效。
工作原理
- 机制:
- 监督训练:使用标注的 NLI 数据来学习反映句子间逻辑关系的句子表征。
- 双向 LSTM:采用递归神经网络从两个方向处理句子,以捕捉上下文。
- 其他细节:该模型利用监督理解来完善嵌入,使语义相似的句子在向量空间中靠得更近,从而大大提高了情感分析和转述检测等任务的性能。
代码实现
您可以按照此 Kaggle Notebook 来实现此功能。
输出:
优势
- 丰富的语义捕捉:提供深入的、上下文细微差别的句子表示。
- 任务优化:擅长捕捉语义推理任务所需的关系。
缺点
- 依赖标记数据:需要大量标注数据集进行训练。
- 计算密集:比无监督方法更耗费资源。
10. 通用句子编码器(USE)
通用句子编码器(USE)是谷歌开发的一种模型,用于创建高质量、通用的句子嵌入。USE 于 2018 年发布,旨在以最小的微调在各种 NLP 任务中良好地运行,使其成为从语义搜索到文本分类等各种应用的通用工具。
工作原理
- 机制:
- 架构选项:USE 可以使用变换器架构或深度平均网络 (DAN) 来实现句子编码。
- 预训练:在大型、多样化的数据集上进行训练,捕捉广泛的语言模式,将句子映射到固定维度的空间中。
- 其他细节:USE 提供跨领域和跨任务的强大嵌入功能,是一种出色的“开箱即用”解决方案。它的设计兼顾了性能和效率,可提供高级嵌入,无需针对具体任务进行大量调整。
代码实现
import tensorflow_hub as hub
import tensorflow as tf
import numpy as np
# Load the model (this may take a few seconds on first run)
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
print("✅ USE model loaded successfully!")
# Sample sentences
sentences = [
"Machine learning is fun.",
"Artificial intelligence and machine learning are related.",
"I love playing football.",
"Deep learning is a subset of machine learning."
]
# Get sentence embeddings
embeddings = embed(sentences)
# Convert to NumPy for easier manipulation
embeddings_np = embeddings.numpy()
# Display shape and first vector
print(f"🔹 Embedding shape: {embeddings_np.shape}")
print(f"🔹 First sentence embedding (truncated):\n{embeddings_np[0][:10]} ...")
from sklearn.metrics.pairwise import cosine_similarity
# Compute pairwise cosine similarities
similarity_matrix = cosine_similarity(embeddings_np)
# Display similarity matrix
import pandas as pd
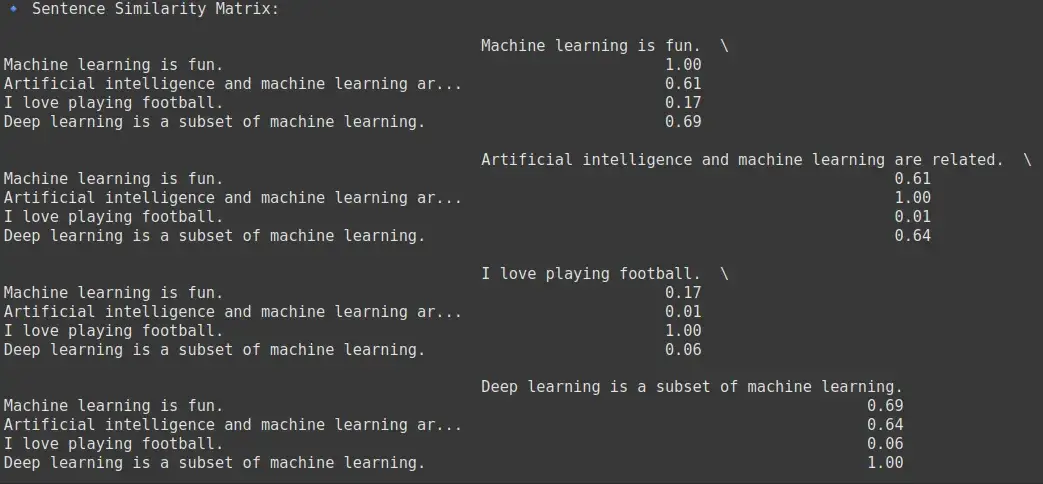
similarity_df = pd.DataFrame(similarity_matrix, index=sentences, columns=sentences)
print("🔹 Sentence Similarity Matrix:\n")
print(similarity_df.round(2))
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Reduce to 2D
pca = PCA(n_components=2)
reduced = pca.fit_transform(embeddings_np)
# Plot
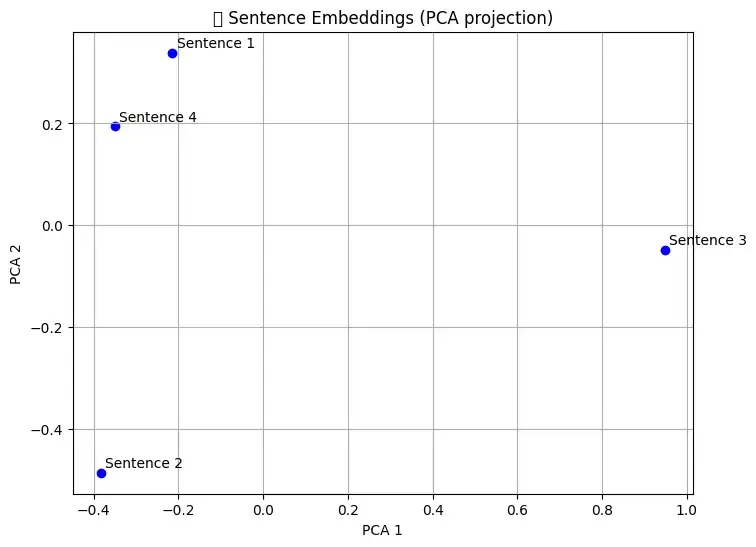
plt.figure(figsize=(8, 6))
plt.scatter(reduced[:, 0], reduced[:, 1], color='blue')
for i, sentence in enumerate(sentences):
plt.annotate(f"Sentence {i+1}", (reduced[i, 0]+0.01, reduced[i, 1]+0.01))
plt.title("📊 Sentence Embeddings (PCA projection)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.grid(True)
plt.show()
输出:

优点
- 多功能性:适用范围广,无需额外培训。
- 预培训的便利性:可立即使用,节省时间和计算资源。
缺点
- 表征固定:每个句子只产生一个嵌入,无法根据不同语境进行动态调整。
- 模型大小:某些变体相当大,这可能会影响在资源有限的环境中的部署。
11. Node2Vec
Node2Vec 最初是为学习图结构中的节点嵌入而设计的一种方法。虽然它本身不是一种文本表示方法,但却越来越多地应用于涉及网络或图数据的 NLP 任务,如社交网络或知识图谱。该方法于 2016 年左右推出,有助于捕捉图数据中的结构关系。
使用案例: 节点分类、链接预测、图聚类、推荐系统。
工作原理
- 机制:
- 随机漫步:在图上执行有偏向的随机行走,生成节点序列。
- 跳过图模型:在这些序列上应用与 Word2Vec 类似的策略,学习节点的低维嵌入。
- 其他细节:通过模拟节点内的句子,Node2Vec 能有效捕捉图的局部和全局结构。它具有很强的自适应能力,可用于各种下游任务,如网络数据中的聚类、分类或推荐系统。
代码实现
我们将使用 NetworkX 现成的图来查看我们的 Node2Vec 实现。要了解有关空手道俱乐部图的更多信息,请单击此处。
!pip install numpy==1.24.3 # Adjust version if needed
import networkx as nx
import numpy as np
from node2vec import Node2Vec
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Create a simple graph
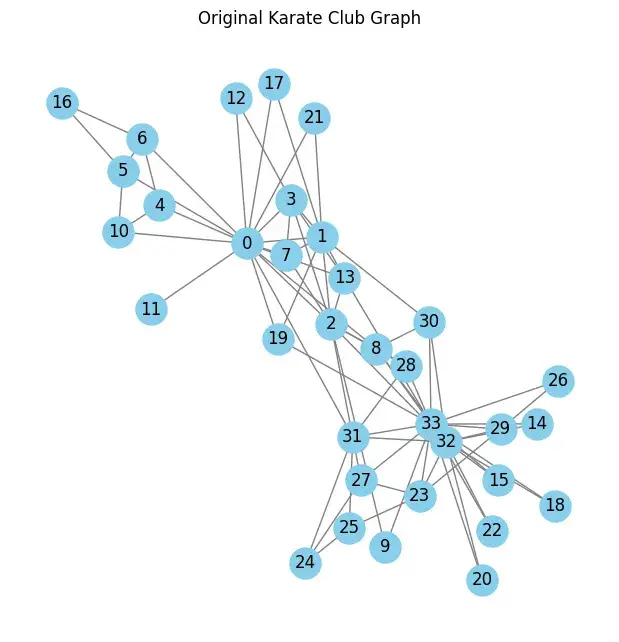
G = nx.karate_club_graph() # A famous test graph with 34 nodes
# Visualize original graph
plt.figure(figsize=(6, 6))
nx.draw(G, with_labels=True, node_color='skyblue', edge_color='gray', node_size=500)
plt.title("Original Karate Club Graph")
plt.show()
# Initialize Node2Vec model
node2vec = Node2Vec(G, dimensions=64, walk_length=30, num_walks=200, workers=2)
# Train the model (Word2Vec under the hood)
model = node2vec.fit(window=10, min_count=1, batch_words=4)
# Get the vector for a specific node
node_id = 0
vector = model.wv[str(node_id)] # Note: Node IDs are stored as strings
print(f"🔹 Embedding for node {node_id}:\n{vector[:10]}...") # Truncated
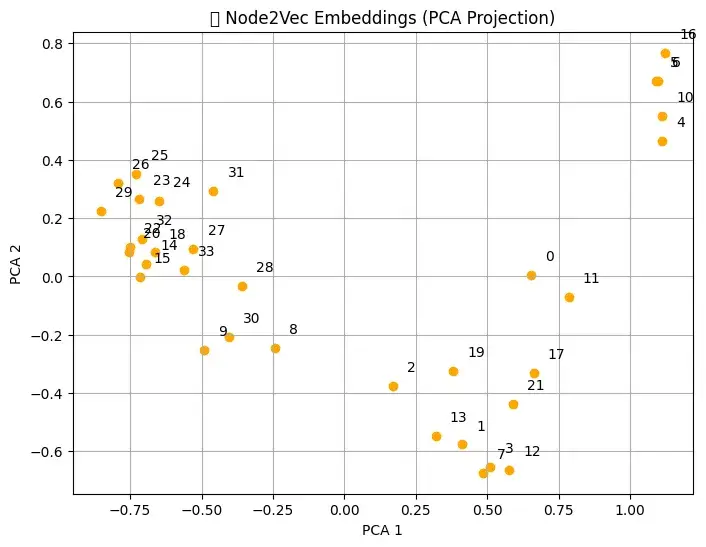
# Get all embeddings
node_ids = model.wv.index_to_key
embeddings = np.array([model.wv[node] for node in node_ids])
# Reduce dimensions to 2D
pca = PCA(n_components=2)
reduced = pca.fit_transform(embeddings)
# Plot embeddings
plt.figure(figsize=(8, 6))
plt.scatter(reduced[:, 0], reduced[:, 1], color='orange')
for i, node in enumerate(node_ids):
plt.annotate(node, (reduced[i, 0] + 0.05, reduced[i, 1] + 0.05))
plt.title("📊 Node2Vec Embeddings (PCA Projection)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.grid(True)
plt.show()
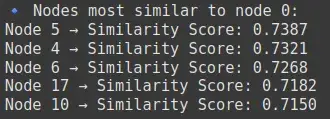
# Find most similar nodes to node 0
similar_nodes = model.wv.most_similar(str(0), topn=5)
print("🔹 Nodes most similar to node 0:")
for node, score in similar_nodes:
print(f"Node {node} → Similarity Score: {score:.4f}")
输出:

优势
- 图形结构捕捉:擅长嵌入具有丰富关系信息的节点。
- 灵活性:可应用于任何图结构数据,而不仅仅是语言。
缺点
- 领域特定性:对纯文本的适用性较差,除非将其表示为图形。
- 参数敏感性:嵌入的质量对随机游走中使用的参数很敏感。
12. ELMo(语言模型嵌入)
ELMo 由艾伦人工智能研究所于 2018 年推出,通过提供深度上下文化的单词表示,标志着一项突破。与早期为每个单词生成单一向量的模型不同,ELMo 生成的动态嵌入会根据句子的上下文发生变化,同时捕捉句法和语义的细微差别。
工作原理
- 机制
- 双向 LSTM:从正向和反向两个方向处理文本,以捕捉完整的上下文信息。
- 分层表示:结合神经网络多个层的表征,每个层捕捉语言的不同方面。
- 其他细节:关键的创新之处在于,同一个词可以根据不同的用法有不同的嵌入,这使得 ELMo 能够更有效地处理歧义和多义词。这种对上下文的敏感性提高了许多下游 NLP 任务的效率。它通过可定制的参数进行操作,包括维度(嵌入向量大小)、walk_length(每次随机行走的节点)、num_walks(每个节点的行走次数)以及偏置参数p(返回因子)和q(进出因子),这些参数通过平衡广度优先(BFS)和深度优先(DFS)的搜索倾向来控制行走行为。该方法将有偏差的随机行走与Word2Vec 的 Skip-gram 架构相结合,从而学习保留网络结构和节点关系的嵌入。Node2Vec 通过捕捉嵌入空间中的局部网络模式和更广泛的结构,实现了有效的节点分类、链接预测和图聚类。
代码实现
全球的 NLP 科学家已经开始将 ELMo 用于各种 NLP 任务,无论是在研究领域还是在工业领域。您必须查看 ELMo 的原始研究论文。
优势
- 语境感知:根据上下文提供不同的单词嵌入。
- 增强性能:基于情感分析、问题解答和机器翻译等多种任务提高结果。
缺点
- 计算要求高:需要更多资源进行训练和推理。
- 架构复杂:与其他更简单的模型相比,在实施和微调方面具有挑战性。
13. BERT及其变体
什么 是 BERT?
BERT 或 Bidirectional Encoder Representations from Transformers,由谷歌于 2018 年发布,通过引入一种基于变压器的架构来捕捉双向语境,从而彻底改变了 NLP。与以往以单向方式处理文本的模型不同,BERT 同时考虑了每个单词的左右上下文。这种深入的上下文理解使 BERT 能够出色地完成从问题解答、情感分析到命名实体识别等各种任务。
工作原理
- 转换器架构:BERT 建立在多层变换器网络的基础上,该网络使用自我关注机制来同时捕捉句子中所有单词之间的依赖关系。这样,模型就能权衡每个词与其他每个词之间的依赖关系。
- 屏蔽语言建模:在预训练过程中,BERT 会随机屏蔽输入中的某些单词,然后根据上下文对其进行预测。这就迫使模型学习双向语境,并对语言模式形成稳健的理解。
- 下一句预测:BERT 还对成对的句子进行训练,学习预测一个句子在逻辑上是否紧跟另一个句子。这有助于捕捉句子之间的关系,这是文档分类和自然语言推理等任务的基本特征。
其他细节:BERT 的架构允许它学习复杂的语言模式,包括语法和语义。对下游任务的微调非常简单,因此在许多基准测试中都取得了一流的性能。
优势
- 深度语境理解:通过考虑过去和未来的语境,BERT 可以生成更丰富、更细致的单词表述。
- 多功能性:只需进行相对较少的额外训练,即可对 BERT 进行微调,以适应各种下游任务。
缺点
- 计算负荷重:该模型在训练和推理过程中都需要大量的计算资源。
- 模型规模大:BERT 的参数数量较多,在资源有限的环境中部署具有挑战性。
SBERT(Sentence-BERT)
Sentence-BERT (SBERT) 于 2019 年推出,旨在解决 BERT 的一个关键局限–即在生成语义上有意义的句子嵌入方面效率低下,无法完成语义相似性、聚类和信息检索等任务。SBERT 对 BERT 的架构进行了调整,以生成固定大小的句子嵌入,并对直接比较句子含义进行了优化。
工作原理
- 连体网络架构:SBERT 采用连体(或三重)网络架构,修改了 BERT 的原始结构。这意味着它可以通过相同的基于 BERT 的编码器并行处理两个(或多个)句子,从而让模型学习嵌入,使语义相似的句子在向量空间中靠得更近。
- 池化操作:通过 BERT 处理句子后,SBERT 对标记嵌入应用池化策略(通常指池化),为每个句子生成固定大小的向量。
- 句对微调:SBERT 在涉及句子对的任务中使用对比损失或三重损失进行微调。这一训练目标可促使模型在嵌入空间中将相似的句子放在更近的位置,而将不相似的句子放在更远的位置。
优势 :
- 高效的句子比较:SBERT 针对语义搜索和聚类等任务进行了优化。由于其固定大小和语义丰富的句子嵌入,比较数以万计的句子在计算上是可行的。
- 下游任务的多功能性:SBERT 嵌入对各种应用都很有效,如转述检测、语义文本相似性和信息检索。
不足之处:
- 依赖微调数据:微调过程中使用的训练数据的领域和质量会严重影响 SBERT 嵌入的质量。
- 资源密集型训练:虽然推理效率很高,但初始微调过程需要大量计算资源。
DistilBERT
DistilBERT 由 Hugging Face 于 2019 年推出,是 BERT 的一个更轻、更快的变体,保留了其大部分性能。它是利用一种称为知识蒸馏的技术创建的,即训练一个较小的模型(学生)来模仿一个较大的、预先训练好的模型(教师)的行为,在本例中就是 BERT。
工作原理
- 知识蒸馏:DistilBERT 的训练目的是与原始 BERT 模型的输出分布相匹配,同时使用更少的参数。它删除了一些层(例如,在 BERT 基础上删除了 6 层而不是 12 层),但保留了关键的学习行为。
- 损失函数:训练使用语言建模损失和蒸馏损失(教师和学生对数之间的 KL 发散)的组合。
- 速度优化:DistilBERT 经过优化,推理速度提高了 60%,同时保留了 BERT 在下游任务中约 97% 的性能。
优势 :
- 轻便快速:由于计算需求降低,因此是实时或移动应用的理想选择。
- 具有竞争力的性能:以显著降低的资源使用率实现接近 BERT 的准确性。
缺点 :
- 精度略有下降:虽然非常接近,但在复杂任务中可能略逊于完整的 BERT 模型。
- 微调灵活性有限:在细分领域的通用性可能不如全尺寸模型。
RoBERTa
RoBERTa 或 Robustly Optimized BERT Pretraining Approach 是由 Facebook AI 于 2019 年推出的,是对 BERT 的稳健增强。它调整了预训练方法,在各种任务中显著提高了性能。
工作原理
- 训练增强 :
- 删除了 “下一句预测”(NSP)目标,该目标在某些情况下会影响性能。
- 在更大的数据集(如普通爬行)上进行更长时间的训练。
- 使用更大的迷你批次和更多的训练步骤来稳定和优化学习。
- 动态屏蔽:与 BERT 的静态屏蔽相比,这种方法在每次训练过程中都会即时应用屏蔽,让模型接触到更多不同的屏蔽模式。
优点
- 卓越性能:在 GLUE 和 SQuAD 等多个基准测试中的表现优于 BERT。
- 强大的学习能力:由于改进了训练数据和策略,跨领域通用性更强。
缺点 :
- 资源密集:计算要求比 BERT 还高。
- 过拟合风险:由于需要大量的训练数据和大型数据集,如果处理不慎,就有可能出现过拟合。
代码执行
from transformers import AutoTokenizer, AutoModel
import torch
# Input sentence for embedding
sentence = "Natural Language Processing is transforming how machines understand humans."
# Choose device (GPU if available)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# =============================
# 1. BERT Base Uncased
# =============================
# model_name = "bert-base-uncased"
# =============================
# 2. SBERT - Sentence-BERT
# =============================
# model_name = "sentence-transformers/all-MiniLM-L6-v2"
# =============================
# 3. DistilBERT
# =============================
# model_name = "distilbert-base-uncased"
# =============================
# 4. RoBERTa
# =============================
model_name = "roberta-base" # Only RoBERTa is active now uncomment other to test other models
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name).to(device)
model.eval()
# Tokenize input
inputs = tokenizer(sentence, return_tensors='pt', truncation=True, padding=True).to(device)
# Forward pass to get embeddings
with torch.no_grad():
outputs = model(**inputs)
# Get token embeddings
token_embeddings = outputs.last_hidden_state # (batch_size, seq_len, hidden_size)
# Mean Pooling for sentence embedding
sentence_embedding = torch.mean(token_embeddings, dim=1)
print(f"Sentence embedding from {model_name}:")
print(sentence_embedding)
输出:
摘要
- BERT:可提供深度双向上下文嵌入,是各种 NLP 任务的理想选择。它通过基于变换器的自我关注捕捉复杂的语言模式,但产生的标记级嵌入需要汇总到句子级任务中。
- SBERT:对 BERT 进行了扩展,将其转化为一个可直接生成有意义句子嵌入的模型。凭借其连体网络架构和对比学习目标,SBERT 在需要对句子进行快速、准确的语义比较的任务中表现出色,例如语义搜索、意译检测和句子聚类。
- DistilBERT:通过使用知识蒸馏技术,为 BERT 提供了一种更轻、更快的替代方案。它保留了 BERT 的大部分性能,同时更适合实时或资源受限的应用。在推理速度和效率是关键因素的情况下,它是理想的选择,不过在复杂场景中可能会略显不足。
- RoBERTa:在 BERT 的基础上进行了改进,修改了预训练机制,通过使用更大的数据集取消了下一句预测任务,并应用了动态屏蔽。这些改动使 BERT 在各种基准测试中具有更好的泛化能力和性能,但代价是增加了计算资源。
其他著名的 BERT 变体
虽然 BERT 及其直接后代(如 SBERT、DistilBERT 和 RoBERTa)在 NLP 领域产生了重大影响,但也出现了其他一些强大的变体,以解决不同的局限性并增强特定功能:
- ALBERT (A Lite BERT):ALBERT 是 BERT 的更高效版本,它通过两项关键创新减少了参数数量:因数化嵌入参数化(将词汇嵌入的大小从隐藏层中分离出来)和跨层参数共享(在转换层之间重复使用权重)。这些改变使 ALBERT 速度更快、内存效率更高,同时保持了在许多 NLP 基准测试中的性能。
- XLNet:与依赖于掩码语言建模的 BERT 不同,XLNet 采用了基于置换的自回归训练策略。这样,它就可以捕捉双向语境,而无需依赖掩码等数据破坏。XLNet 还融合了 Transformer-XL 的理念,这使它能够建立长期依赖关系模型,并在多项 NLP 任务中表现优于 BERT。
- T5(Text-to-Text Transfer Transformer):由谷歌研究院开发,T5将从翻译到分类的所有 NLP 任务都视为文本到文本的问题。例如,T5 不会直接生成分类标签,而是通过学习将标签生成为单词或短语。这种统一的方法使其具有高度的灵活性和强大的功能,能够应对广泛的 NLP 挑战。
14. CLIP和BLIP
CLIP(对比语言-图像预训练)和 BLIP(引导语言-图像预训练)等现代多模态模型代表了嵌入技术的最新前沿。它们在文本数据和视觉数据之间架起了一座桥梁,使涉及语言和图像的任务成为可能。这些模型已成为图像搜索、字幕和视觉问题解答等应用的关键。
工作原理
- CLIP:
- 机制:在大型图像-文本对数据集上进行训练,利用对比学习将图像嵌入与相应的文本嵌入对齐。
- 过程:模型学习将图像和文本映射到一个共享的向量空间,在这个空间中,相关的图像和文本对更接近。
- BLIP:
- 机制:使用引导方法,通过迭代训练完善语言与视觉之间的对齐。
- 过程:在初始对齐的基础上进行改进,以实现更准确的多模态表征。
- 其他细节:这些模型利用变换器的力量来处理文本,利用卷积网络或基于变换器的网络来处理图像。它们联合推理文本和视觉内容的能力为多模态人工智能研究开辟了新的可能性。
代码实现
from transformers import CLIPProcessor, CLIPModel
# from transformers import BlipProcessor, BlipModel # Uncomment to use BLIP
from PIL import Image
import torch
import requests
# Choose device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load a sample image and text
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/cat_style_layout.png"
image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB")
text = "a cute puppy"
# ===========================
# 1. CLIP (for Embeddings)
# ===========================
clip_model_name = "openai/clip-vit-base-patch32"
clip_model = CLIPModel.from_pretrained(clip_model_name).to(device)
clip_processor = CLIPProcessor.from_pretrained(clip_model_name)
# Preprocess input
inputs = clip_processor(text=[text], images=image, return_tensors="pt", padding=True).to(device)
# Get text and image embeddings
with torch.no_grad():
text_embeddings = clip_model.get_text_features(input_ids=inputs["input_ids"])
image_embeddings = clip_model.get_image_features(pixel_values=inputs["pixel_values"])
# Normalize embeddings (optional)
text_embeddings = text_embeddings / text_embeddings.norm(dim=-1, keepdim=True)
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
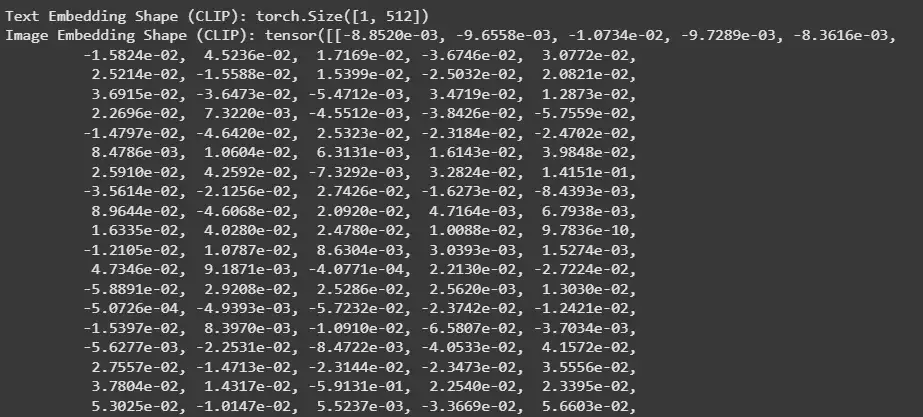
print("Text Embedding Shape (CLIP):", text_embeddings.shape)
print("Image Embedding Shape (CLIP):", image_embeddings)
# ===========================
# 2. BLIP (commented)
# ===========================
# blip_model_name = "Salesforce/blip-image-text-matching-base"
# blip_processor = BlipProcessor.from_pretrained(blip_model_name)
# blip_model = BlipModel.from_pretrained(blip_model_name).to(device)
# inputs = blip_processor(images=image, text=text, return_tensors="pt").to(device)
# with torch.no_grad():
# text_embeddings = blip_model.text_encoder(input_ids=inputs["input_ids"]).last_hidden_state[:, 0, :]
# image_embeddings = blip_model.vision_model(pixel_values=inputs["pixel_values"]).last_hidden_state[:, 0, :]
# print("Text Embedding Shape (BLIP):", text_embeddings.shape)
# print("Image Embedding Shape (BLIP):", image_embeddings)
输出:
优点
- 跨模态理解:提供跨文本和图像的强大表征。
- 适用性广:适用于图像检索、字幕和其他多模态任务。
缺点
- 复杂性高:训练需要大量经过精心整理的配对数据集。
- 资源需求大:多模态模型是计算要求最高的模型之一。
各种嵌入技术比较
| 嵌入技术 | 类型 | 模型架构/方法 | 常见用例 |
|---|---|---|---|
| Count Vectorizer | 独立于上下文,无 ML | 基于计数 (Bag of Words) | 用于搜索、聊天机器人和语义相似性的句子嵌入 |
| One-Hot Encoding | 独立于上下文,无 ML | 手动编码 | 基准模型、基于规则的系统 |
| TF-IDF | 独立于上下文,无 ML | 计数 + 反向文档频率 | 文档排名、文本相似性、关键词提取 |
| Okapi BM25 | 独立于上下文,统计排序 | 概率 IR 模型 | 搜索引擎、信息检索 |
| Word2Vec (CBOW, SG) | 独立于上下文,基于 ML | 神经网络(浅层) | 情感分析、词语相似性、NLP 管道 |
| GloVe | 独立于上下文,基于 ML | 全局共现矩阵 + ML | 词语相似性、嵌入初始化 |
| FastText | 独立于上下文,基于 ML | Word2Vec + 子词嵌入 | 形态丰富的语言、OOV 词处理 |
| Doc2Vec | 独立于上下文,基于 ML | 针对文档的 Word2Vec 扩展 | 文档分类、聚类 |
| InferSent | 上下文无关,基于 RNN | 带监督学习的 BiLSTM | 语义相似性、NLI 任务 |
| Universal Sentence Encoder | 上下文无关,基于 Transformer | Transformer/DAN(深度平均网络) | 用于搜索的句子嵌入、聊天机器人、语义相似性 |
| Node2Vec | 基于图形的嵌入 | 随机行走 + Skipgram | 图表示、推荐系统、链接预测 |
| ELMo | 上下文无关、基于 RNN | 双向 LSTM | 命名实体识别、问题解答、核心参照解析 |
| BERT & Variants | 上下文相关,基于 Transformer | 问答、情感分析、摘要和语义搜索 | 问答、情感分析、总结、语义搜索 |
| CLIP | 多模态,基于 Transformer | 视觉 + 文本编码器(对比) | 图像标题、跨模态搜索、文本到图像检索 |
| BLIP | 多模态,基于 Transformer | 视觉语言预训练(VLP) | 图像标题、VQA(视觉问题解答) |
小结
从基于计数的基本方法(如单次编码)到如今功能强大、上下文感知、甚至多模态的模型(如 BERT 和 CLIP),嵌入式技术已经走过了漫长的道路。每一步都是为了突破上一步的局限,帮助我们更好地理解和表达人类语言。如今,得益于 Hugging Face 和 Ollama 等平台,我们可以访问越来越多的前沿嵌入模型库,从而比以往任何时候都更容易进入语言智能的新时代。
不过,除了了解这些技术的工作原理,我们还应该考虑它们如何与我们的实际目标相匹配。无论您是在构建聊天机器人、语义搜索引擎、推荐系统还是文档摘要系统,总有一种嵌入技术能将我们的想法变为现实。毕竟,在当今的语言技术世界中,每一种设想都有一个真正的载体。













暂无评论内容