

数据预处理对于机器学习的成功至关重要,但现实世界的数据集往往包含错误。使用 Cleanlab 进行数据预处理提供了一种高效的解决方案,它利用 Python 软件包实现了自信学习算法。通过自动检测和纠正标签错误,Cleanlab 简化了机器学习中的数据预处理过程。通过使用统计方法识别有问题的数据点,Cleanlab 可以使用 Cleanlab Python 进行数据预处理,从而提高模型的可靠性。例如,Cleanlab 可简化工作流程,以最小的投入提高机器学习的成果。
数据预处理为何重要?
数据预处理直接影响模型性能。带有错误标签、异常值和不一致性的不洁数据会导致糟糕的预测和不可靠的见解。在有缺陷的数据上训练出来的模型会延续这些错误,在整个系统中产生不准确的连带效应。高质量的预处理可以在建模开始前消除这些问题。
有效的预处理还能节省时间和资源。更干净的数据意味着更少的模型迭代、更快的训练和更低的计算成本。预处理还能避免在调试复杂模型时遇到的挫折,因为真正的问题在于数据本身。预处理将原始数据转化为有价值的信息,使算法能够有效地从中学习。
如何使用Cleanlab进行数据预处理?
Cleanlab 可以在训练前清理和验证数据。它能利用 ML 模型发现不良标签、重复数据和低质量样本。它最适用于标签和数据质量检查,而非基本的文本清理。
Cleanlab 的主要功能
- 检测错误标签数据(噪声标签)
- 标记重复数据和异常值
- 检查低质量或不一致样本
- 提供标签分布洞察
- 与任何 ML 分类器配合使用,提高数据质量
现在,让我们逐步介绍如何使用 Cleanlab。
第 1 步:安装库
在开始之前,我们需要安装一些必要的库。这些库将帮助我们加载数据并顺利运行 Cleanlab 工具。
!pip install cleanlab !pip install pandas !pip install numpy
- cleanlab:用于检测标签和数据质量问题。
- pandas:用于读取和处理 CSV 数据。
- numpy:支持 Cleanlab 使用的快速数值计算。
第 2 步:加载数据集
现在,我们使用 Pandas 加载数据集,开始预处理。
import pandas as pd
# Load dataset
df = pd.read_csv("/content/Tweets.csv")
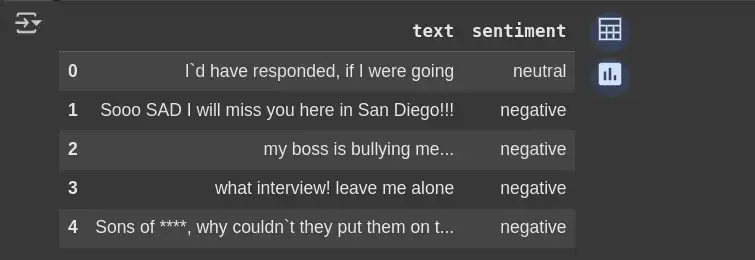
df.head(5)
- pd.read_csv():
- df.head(5):

现在,一旦我们加载了数据。我们将只关注我们需要的列,并检查是否有缺失值。
# Focus on relevant columns df_clean = df.drop(columns=['selected_text'], axis=1, errors='ignore') df_clean.head(5)
如果 selected_text 列存在,则删除该列;如果不存在,则避免出错。有助于只保留必要的列进行分析。
第 3 步:检查标签问题
from cleanlab.dataset import health_summary
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.preprocessing import LabelEncoder
# Prepare data
df_clean = df.dropna()
y_clean = df_clean['sentiment'] # Original string labels
# Convert string labels to integers
le = LabelEncoder()
y_encoded = le.fit_transform(y_clean)
# Create model pipeline
model = make_pipeline(
TfidfVectorizer(max_features=1000),
LogisticRegression(max_iter=1000)
)
# Get cross-validated predicted probabilities
pred_probs = cross_val_predict(
model,
df_clean['text'],
y_encoded, # Use encoded labels
cv=3,
method="predict_proba"
)
# Generate health summary
report = health_summary(
labels=y_encoded, # Use encoded labels
pred_probs=pred_probs,
verbose=True
)
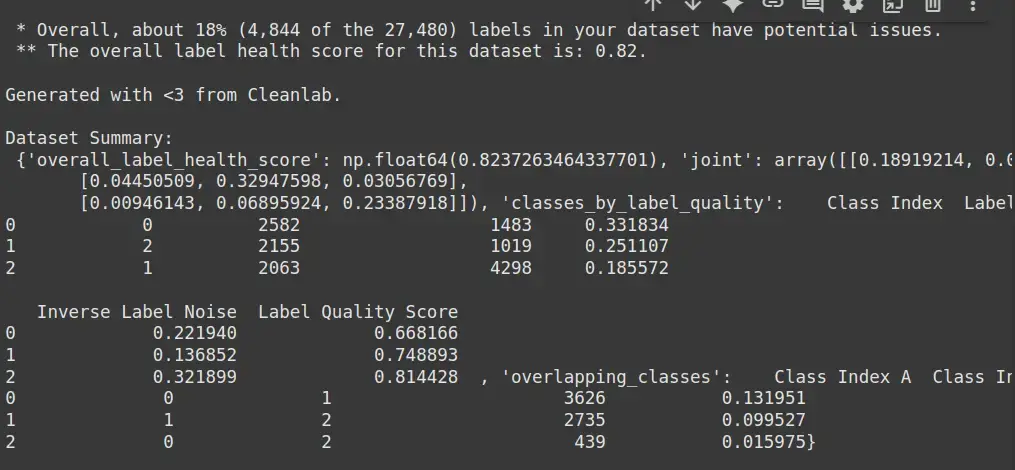
print("Dataset Summary:\n", report)
- df.dropna():删除有缺失值的行,确保训练数据的干净。
- LabelEncoder():将字符串标签(如“positive”、“negative”)转换为整数标签,以便与模型兼容。
- make_pipeline():创建带有 TF-IDF 向量器(将文本转换为数字特征)和逻辑回归模型的管道。
- cross_val_predict():执行 3 倍交叉验证,并返回预测概率而非标签。
- health_summary():使用 Cleanlab 分析预测概率和标签,识别潜在的标签问题,如错误标签。
- print(report): 显示健康摘要报告,突出显示数据集中的任何标签不一致或错误。
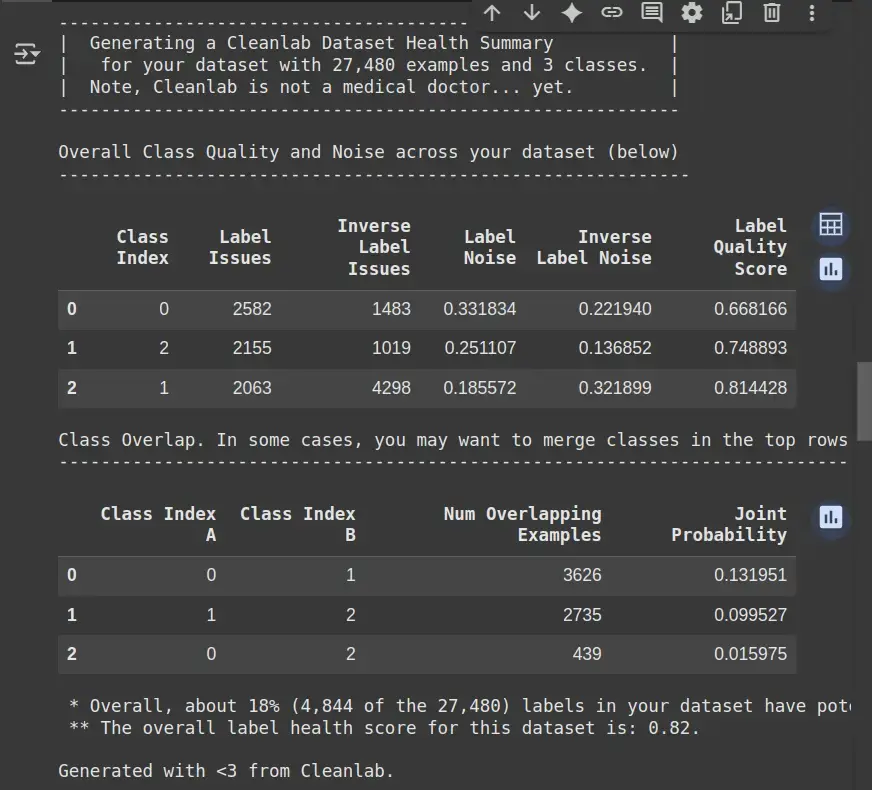
- Label Issues:表示一个类别中有多少样本的标签可能不正确或含糊不清。
- Inverse Label Issues:显示预测标签不正确(与真实标签相反)的实例数量。
- Label Noise:衡量每个类别中的噪声(错误标签或不确定性)程度。
- Label Quality Score:反映一个类别中标签的整体质量(分数越高表示质量越好)。
- Class Overlap:确定不同类别之间重叠的示例数量,以及发生此类重叠的概率。
- Overall Label Health Score:提供数据集标签质量的总体指示(分数越高,表示标签健康状况越好)。
第 4 步:检测低质量样本
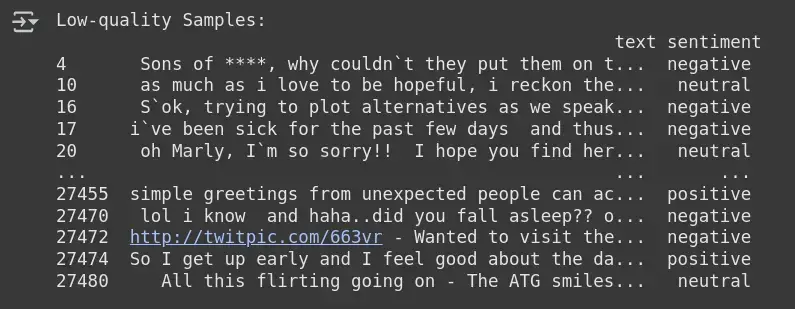
这一步涉及检测和隔离数据集中可能存在标签问题的样本。Cleanlab 使用预测概率和真实标签来识别低质量样本,然后对其进行审查和清理。
# Get low-quality sample indices
from cleanlab.filter import find_label_issues
issue_indices = find_label_issues(labels=y_encoded, pred_probs=pred_probs)
# Display problematic samples
low_quality_samples = df_clean.iloc[issue_indices]
print("Low-quality Samples:\n", low_quality_samples)
- find_label_issues():Cleanlab 中的一个函数,用于通过比较预测概率(pred_probs)和真实标签(y_encoded),检测存在标签问题的样本索引。
- issue_indices:存储被 Cleanlab 识别为存在潜在标签问题(即低质量样本)的样本指数。
- df_clean.iloc[issue_indices]:使用低质量样本的索引从干净数据集 (df_clean) 中提取有问题的行。
- low_quality_samples:保存被识别为存在标签问题的样本,可对其进行进一步审核,以进行潜在的修正。
第 5 步:通过模型预测检测噪声标签
这一步涉及使用 CleanLearning(一种 Cleanlab 方法),通过训练模型和使用其预测来识别不一致或有噪声标签的样本,从而检测数据集中的噪声标签。
from cleanlab.classification import CleanLearning
from cleanlab.filter import find_label_issues
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
# Encode labels numerically
le = LabelEncoder()
df_clean['encoded_label'] = le.fit_transform(df_clean['sentiment'])
# Vectorize text data
vectorizer = TfidfVectorizer(max_features=3000)
X = vectorizer.fit_transform(df_clean['text']).toarray()
y = df_clean['encoded_label'].values
# Train classifier with CleanLearning
clf = LogisticRegression(max_iter=1000)
clean_model = CleanLearning(clf)
clean_model.fit(X, y)
# Get prediction probabilities
pred_probs = clean_model.predict_proba(X)
# Find noisy labels
noisy_label_indices = find_label_issues(labels=y, pred_probs=pred_probs)
# Show noisy label samples
noisy_label_samples = df_clean.iloc[noisy_label_indices]
print("Noisy Labels Detected:\n", noisy_label_samples.head())
- 标签编码(LabelEncoder()):将字符串标签(如“positive”、“negative”)转换为数值,使其适用于机器学习模型。
- 矢量化(TfidfVectorizer()):使用 TF-IDF 将文本数据转换为数值特征,重点关注 “文本 ”列中最重要的 3000 个特征。
- 训练分类器(LogisticRegression()):使用逻辑回归作为分类器,利用编码标签和矢量化文本数据训练模型。
- CleanLearning (CleanLearning()):将 CleanLearning 应用于逻辑回归模型。该方法通过在训练过程中考虑噪声标签来完善模型处理噪声标签的能力。
- 预测概率 (predict_proba()):训练完成后,模型会预测每个样本的类概率,用于识别潜在的噪声标签。
- find_label_issues():使用预测概率和真实标签来检测哪些样本存在噪声标签(即可能的错误标签)。
- 显示噪声标签:根据索引检索并显示带有噪声标签的样本,以便查看并可能对其进行清理。
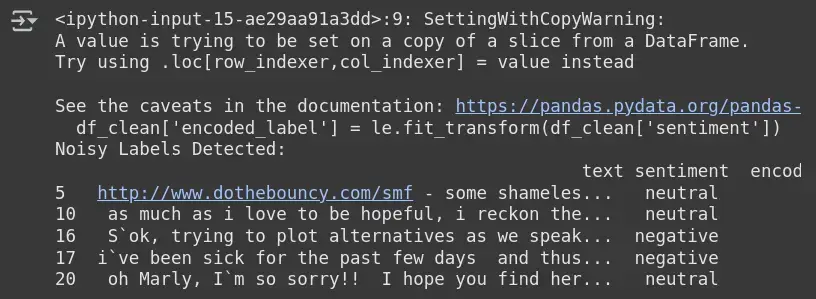
观察
输出: 噪音标签检测
- Cleanlab 会标记预测情感(来自模型)与提供标签不匹配的样本。
- 举例说明: 第 5 行被标记为中性,但模型认为可能不是。
- 根据模型行为,这些样本很可能被误标或含糊不清。
- 这有助于识别、重新标注或删除有问题的样本,以提高模型性能。
小结
预处理是构建可靠机器学习模型的关键。它能消除不一致、规范输入并提高数据质量。但大多数工作流程都忽略了一点,那就是噪声标签。Cleanlab 填补了这一空白。它能自动检测错误标签数据、异常值和低质量样本。无需人工检查。这能让你的数据集更干净,让你的模型更智能。
Cleanlab 预处理不仅能提高准确率,还能节省时间。通过尽早去除不良标签,可以减少训练负荷。更少的错误意味着更快的收敛。信号更多,噪音更少。更好的模型,更少的工作量。













暂无评论内容