
清理数据并不复杂。掌握用于数据清理的 Python 单行程序可以大大加快工作流程,并保持代码的整洁。本博客将重点介绍用于数据清理的最有用的 Python 单行代码,帮助您在一行代码中处理缺失值、重复数据、格式化问题等。我们将探讨适合初学者和专家的 Pandas 数据清理单行示例。您还将发现基本的 Python 数据清理库,让预处理变得高效而直观。准备好以更智能而非更困难的方式清理数据了吗?让我们深入了解紧凑而强大的单行代码!
数据清理为何重要?
在深入了解数据清理流程之前,了解数据清理为何是准确分析和机器学习的关键至关重要。原始数据集通常比较混乱,其中的缺失值、重复数据和不一致的格式可能会扭曲结果。正确的数据清理可确保为分析奠定可靠的基础,提高算法性能和洞察力。
我们将探讨的单行代码能以最少的代码解决常见的数据问题,使数据预处理更快、更高效。现在,让我们来看看清理数据集的步骤,轻松地将数据集转换为干净、分析就绪的形式。
数据清理的单行解决方案
1. 使用dropna()处理缺失数据
现实世界中的数据集很少是完美无缺的。你会面临的最常见问题之一就是缺失值,无论是由于数据收集、数据集合并中的错误,还是手动输入造成的。幸运的是,Pandas 提供了一个简单而强大的方法来处理这个问题:dropna()。
但是 dropna() 可以使用多个参数。让我们来探索如何充分利用它。
- axis
指定删除行还是列:
- axis=0: 丢弃行(默认值)
- axis=1: 删除列
代码:
df.dropna(axis=0) # Drops rows df.dropna(axis=1) # Drops columns
- how
定义要删除的条件:
- how=’any’: 如果缺少任何值,则删除(默认)
- how=’all’: 仅当所有值都缺失时才丢弃
代码:
df.dropna(how='any') # Drop if at least one NaN df.dropna(how='all') # Drop only if all values are NaN
- thresh
指定保留行/列所需的最小非 NAN 值个数。
代码:
df.dropna(thresh=3) # Keep rows with at least 3 non-NaN values
注意:不能同时使用 how 和 thresh。
- subset
仅将条件应用于特定列(或行,如果轴=1)。
代码:
df.dropna(subset=['col1', 'col2']) # Drop rows if NaN in col1 or col2#import csv
2. 使用fillna()处理缺失数据
您可以使用 Pandas 的 fillna() 方法填补缺失数据,而不是丢弃缺失数据。当你想估算值而不是丢失数据时,这个方法尤其有用。
让我们来探讨一下如何使用不同参数的 fillna() 方法。
- subset
指定一个标量、字典、数列或计算值(如平均值、中位数或模式)来填补缺失数据。
代码:
df.fillna(0) # Fill all NaNs with 0
df.fillna({'col1': 0, 'col2': 99}) # Fill col1 with 0, col2 with 99
# Fill with mean, median, or mode of a column
df['col1'].fillna(df['col1'].mean(), inplace=True)
df['col2'].fillna(df['col2'].median(), inplace=True)
df['col3'].fillna(df['col3'].mode()[0], inplace=True) # Mode returns a Series
- method
用于向前或向后传播非空值:
- ‘ffill’ 或 ‘pad’: 正向填充
- ‘bfill’ 或 ‘backfill’:向后填充
代码:
df.fillna(method='ffill') # Fill forward df.fillna(method='bfill') # Fill backward
- axis
选择填充方向:
- axis=0:向下填充(行方向,默认值)
- axis=1:横向填充(列向填充)
代码:
df.fillna(method='ffill', axis=0) # Fill down df.fillna(method='bfill', axis=1) # Fill across
- limit
前向/后向填充中最多可填充的 NaN 个数。
代码:
df.fillna(method='ffill', limit=1) # Fill at most 1 NaN in a row/column#import csv
3. 使用drop_duplicates()删除重复值
使用 drop_duplicates() 函数轻松删除数据集中的重复行,只需一行代码就能确保数据的干净和唯一性。
让我们探讨如何使用不同的参数来使用 drop_dupliucates
- subset
指定查找重复数据的特定列。
- 默认值: 检查所有列
- 使用单列或列列表
代码 :
df.drop_duplicates(subset='col1') # Check duplicates only in 'col1' df.drop_duplicates(subset=['col1', 'col2']) # Check based on multiple columns
- keep
决定保留哪个副本:
- ‘first’ (default): 保留第一次出现的副本
- ‘last’:保留最后一次重复
- False:删除所有重复
代码:
df.drop_duplicates(keep='first') # Keep first duplicate df.drop_duplicates(keep='last') # Keep last duplicate df.drop_duplicates(keep=False) # Drop all duplicates
4. 使用replace()替换特定值
您可以使用 replace() 替换 DataFrame 或 Series 中的特定值。
代码:
# Replace a single value
df.replace(0, np.nan)
# Replace multiple values
df.replace([0, -1], np.nan)
# Replace with dictionary
df.replace({'A': {'old': 'new'}, 'B': {1: 100}})
# Replace in-place
df.replace('missing', np.nan, inplace=True)#import csv
5. 使用astype()更改数据类型
更改列的数据类型有助于确保正确操作和内存效率。
代码:
df['Age'] = df['Age'].astype(int) # Convert to integer df['Price'] = df['Price'].astype(float) # Convert to float df['Date'] = pd.to_datetime(df['Date']) # Convert to datetime
6. 使用str.strip()删除字符串中的空格
在数据集中,字符串值中不需要的前导空格或尾部空格会导致排序、比较或分组问题。str.strip() 方法可以有效地删除这些空格。
代码 :
df['col'].str.lstrip() # Removes leading spaces df['col'].str.rstrip() # Removes trailing spaces df['col'].str.strip() # Removes both leading & trailing
7.清理和提取列值
通过删除不需要的字符或使用正则表达式提取特定模式,可以清理列值。
代码:
# Remove punctuation
df['col'] = df['col'].str.replace(r'[^\w\s]', '', regex=True)
# Extract the username part before '@' in an email address
df['email_user'] = df['email'].str.extract(r'(^[^@]+)')
# Extract the 4-digit year from a date string
df['year'] = df['date'].str.extract(r'(\d{4})')
# Extract the first hashtag from a tweet
df['hashtag'] = df['tweet'].str.extract(r'#(\w+)')
# Extract phone numbers in the format 123-456-7890
df['phone'] = df['contact'].str.extract(r'(\d{3}-\d{3}-\d{4})')
8. 映射和替换值
您可以映射或替换列中的特定值,以规范或转换数据。
代码 :
df['Gender'] = df['Gender'].map({'M': 'Male', 'F': 'Female'})
df['Rating'] = df['Rating'].map({1: 'Bad', 2: 'Okay', 3: 'Good'})
9.处理异常值
异常值会扭曲统计分析和模型性能。以下是处理异常值的常用方法:
- Z-score 法
代码:
# Keep only numeric columns, remove rows where any z-score > 3 df = df[(np.abs(stats.zscore(df.select_dtypes(include=[np.number]))) < 3).all(axis=1)]
- 剪切异常值(封顶至一定范围)
代码:
df['col'].clip(lower=df['col'].quantile(0.05),upper=df['col'].quantile(0.95))
10. 使用Lambda应用函数
Lambda 函数与 apply() 配合使用,可快速转换或操作列中的数据。lambda 函数起转换作用,而 apply() 则将其应用于整个列。
代码:
df['col'] = df['col'].apply(lambda x: x.strip().lower()) # Removes extra spaces and converts text to lowercase
问题陈述
现在,您已经了解了这些 Python 单行代码,让我们来看看问题陈述并尝试解决它。您从一个在线零售平台获得了一个客户数据集。数据存在以下问题
- 电子邮件、年龄、推特和电话等列中存在缺失值。
- 重复条目(如相同的姓名和电子邮件)。
- 格式不一致(如姓名中的空白、字符串中的“missing”)。
- 数据类型问题(例如,Join_Date 值无效)。
- Age 和 Purchase_Amount 中的异常值。
- 需要使用 regex 清理和提取的文本数据(例如,从 Tweet 中提取标签,从电子邮件中提取用户名)。
您的任务是演示如何清理该数据集。
解决方案
有关完整的解决方案,请参阅此Google Colab notebook。它将引导您完成使用 Python 和 pandas 有效清理数据集所需的每个步骤。
按照以下说明清理数据集
- 删除所有值缺失的行
df.dropna(how='all', inplace=True)
- 将 ‘missing’ 或 ‘not available’ 等占位符文本标准化为 NaN
df.replace(['missing', 'not available', 'NaN'], np.nan, inplace=True)
- 填补缺失值
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Email'] = df['Email'].fillna('unknown@example.com')
df['Gender'] = df['Gender'].fillna(df['Gender'].mode()[0])
df['Purchase_Amount'] = df['Purchase_Amount'].fillna(df['Purchase_Amount'].median())
df['Join_Date'] = df['Join_Date'].fillna(method='ffill')
df['Tweet'] = df['Tweet'].fillna('No tweet')
df['Phone'] = df['Phone'].fillna('000-000-0000')
- 删除重复内容
df.drop_duplicates(inplace=True)
- 删除空格,规范文本字段
df['Name'] = df['Name'].apply(lambda x: x.strip().lower() if isinstance(x, str) else x) df['Feedback'] = df['Feedback'].str.replace(r'[^\w\s]', '', regex=True)
- 转换数据类型
df['Age'] = df['Age'].astype(int) df['Purchase_Amount'] = df['Purchase_Amount'].astype(float) df['Join_Date'] = pd.to_datetime(df['Join_Date'], errors='coerce')
- 修复无效值
df = df[df['Age'].between(10, 100)] # realistic age df = df[df['Purchase_Amount'] > 0] # remove negative or zero purchases
- 利用 Z 值去除离群值
numeric_cols = df[['Age', 'Purchase_Amount']] z_scores = np.abs(stats.zscore(numeric_cols)) df = df[(z_scores < 3).all(axis=1)]
- Regex 提取
df['Email_Username'] = df['Email'].str.extract(r'^([^@]+)')
df['Join_Year'] = df['Join_Date'].astype(str).str.extract(r'(\d{4})')
df['Formatted_Phone'] = df['Phone'].str.extract(r'(\d{3}-\d{3}-\d{4})')
- ‘Name’ 的最后清理
df['Name'] = df['Name'].apply(lambda x: x if isinstance(x, str) else 'unknown')
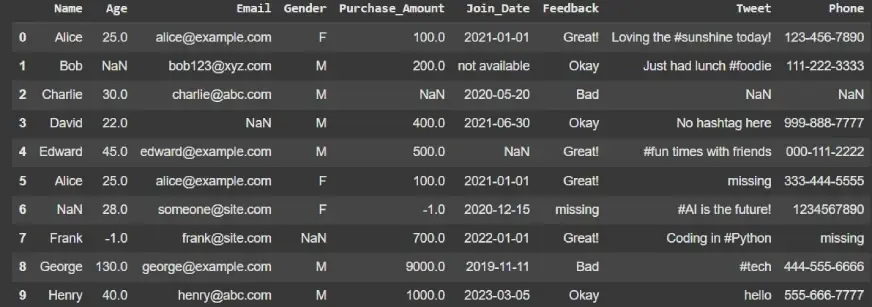
清理前的数据集
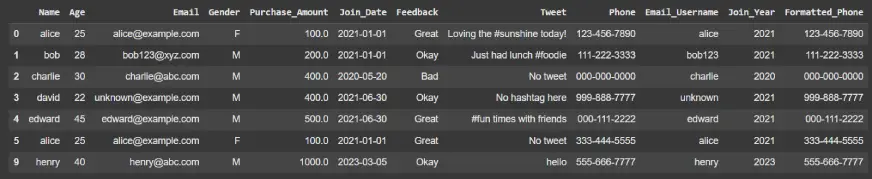
清理后的数据集
小结
清理数据是任何数据分析或机器学习项目的关键步骤。通过掌握这些功能强大的 Python 数据清理单行程序,您可以简化数据预处理工作流程,确保数据准确、一致,并为分析做好准备。从处理缺失值和重复值到删除异常值和格式化问题,这些单行代码让您无需编写冗长的代码就能高效地清理数据。利用 Pandas 和正则表达式的强大功能,您可以保持代码干净、简洁并易于维护。无论您是初学者还是专家,这些方法都能帮助您更智能、更快速地清理数据。













暂无评论内容